Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
5 must-have features for a data importer

Eric Crane
Co-Founder & COO
Share to
What's missing in your data import solution?
Do you have a data importer that's as intuitive, fast and accurate as possible? Does it require the minimum amount of maintenance from your in-house engineers so you can focus on building the product features your customers love?
If your answer to either of these questions was anything other than a resolute "yes," then you might want to keep reading! This article explores different methods for handling data file exchange and explains what a pre-built data importer that requires no patchwork open-source coding can do.
Instead of relying on complex workarounds or home-built importers, here are the top five features you should vet when you choose a data importer for your web-based app.
What is a data importer?
A data importer helps users upload offline data or data from another online source into an application database. The user might be a customer, an internal employee or a customer success representative offering white-glove onboarding assistance to a customer.
Companies need to onboard all sorts of data, but that type of data depends on the application accepting it. Uploaded data could include email subscribers, customer contacts, inventory data, SKUs, task lists, etc.
There are a few common ways businesses today handle data imports, including:
Custom-developed solutions: Engineering teams often custom-build their data importer using patchwork open-source solution. This process is frequently complicated; a comprehensive importer requires UI and application code to handle data normalization, parsing and mapping. Building a solution in-house can be resource-intensive and time-consuming, often keeping engineers from working on their core product features.
Pre-built data importers: A ready-to-go data importer from a third-party vendor is another method businesses use to handle data file imports. This reduces the need for manual uploading and means your in-house engineers won't spend months building it.
A mix of manual and productized: In some cases, software companies might use a mix of manual and pre-built data importing solutions. For example, they may have a spreadsheet with templated columns and request that customers add their data according to the spreadsheet's requirements before uploading it.
Manual processes: Finally, there's the option of doing everything manually, which is surprisingly common. Manual processes don't just refer specifically to uploading data; they refer to everything from data preparation and cleaning to getting the data into a target software application.
What are key data import challenges?
Where to begin?
Importing data is always full of challenges. While there can be endless technical difficulties, the core issues all come down to the effect challenges have on these three categories:
Paying customers
Internal software users
The engineering team
Let's explore these issues a little further.
Time-to-value for customers
When it's difficult for customers to import their data—either because of time-consuming manual processes or because a custom-built data importing feature is difficult to use, everyone loses.
The customer loses because they can't get value out of the product, and the business loses because this customer is more likely to churn (if they ever get started in the first place).
Employee efficiency (in the case of internal tool usage)
Similarly, when the user is an employee and the software was built or purchased for internal use, slow data imports can cause problems. In this case, the business isn't losing money directly from churning customers but indirectly from employees who spend exorbitant amounts of time managing imports.
Work prioritization for the engineering team
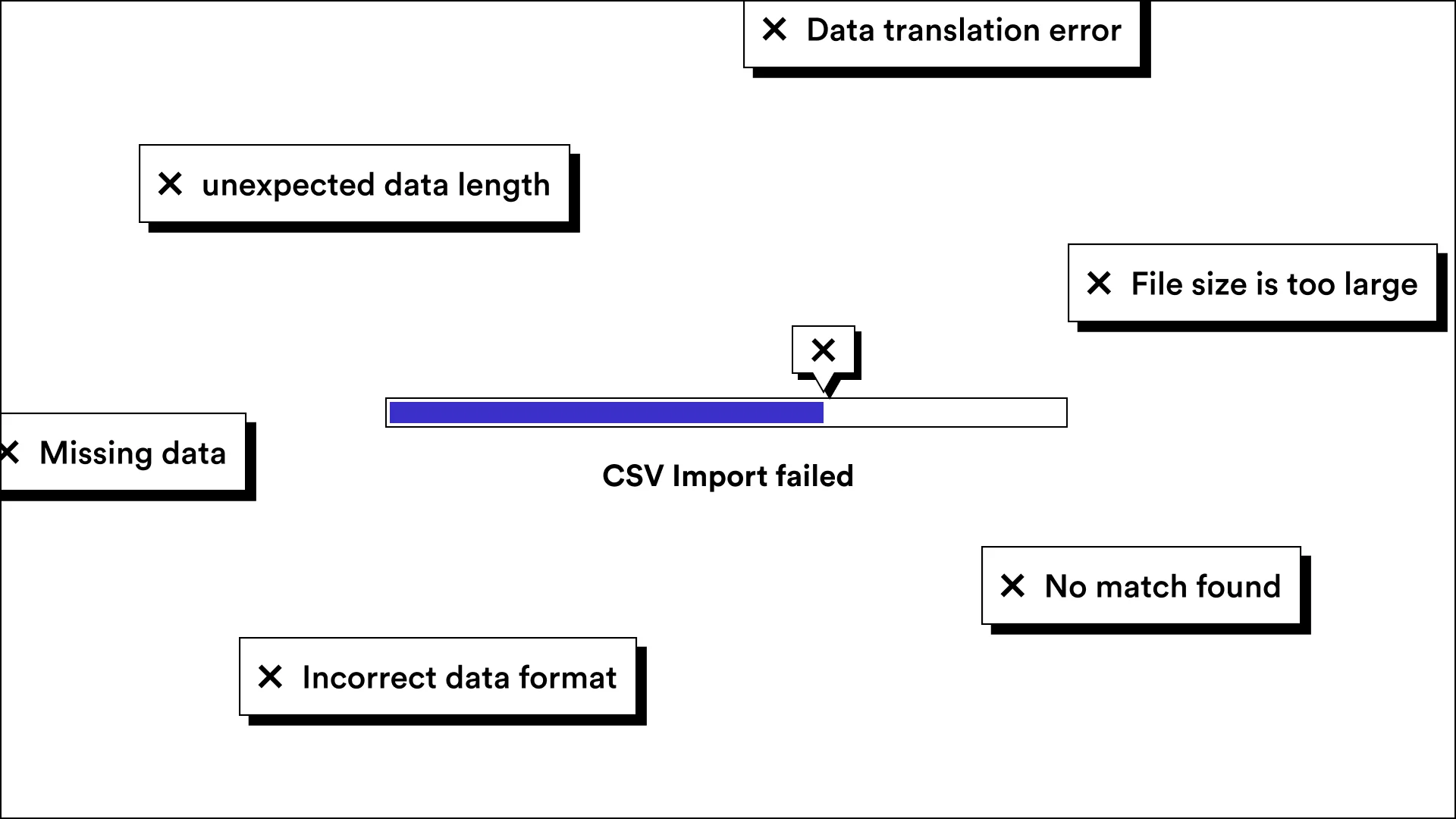
On the flip side of the user perspective comes the engineering team. Data importers are incredibly time-consuming to build because they are technically complicated and challenging to design intuitively, with so many points of failure.
Engineers need to provide seemingly endless error messages so that customers know exactly what went wrong with their data import and how to fix the files. When the data import UX isn't elegantly crafted, end-user customers leave with more questions than answers.
Many engineering teams combine different open-source solutions to speed up the build, but challenges abound.
Open source has made it easier for people to build out homegrown solutions, but those open-source libraries only address small, discrete parts of a data import workflow. For example, you might be able to find an open-source library that does the parsing of Excel files and nothing more, leaving your team to build out the rest.
Why you should consider a ready-made data importer
A pre-built data importer can save time for both customers and the engineering team.
While custom-built solutions cost engineering time and may or may not solve customer problems (depending on how intuitively they're built and how helpful the import error messages are), manual processes save big on engineering time but ultimately cost the customer time in a way that can negatively impact revenue.
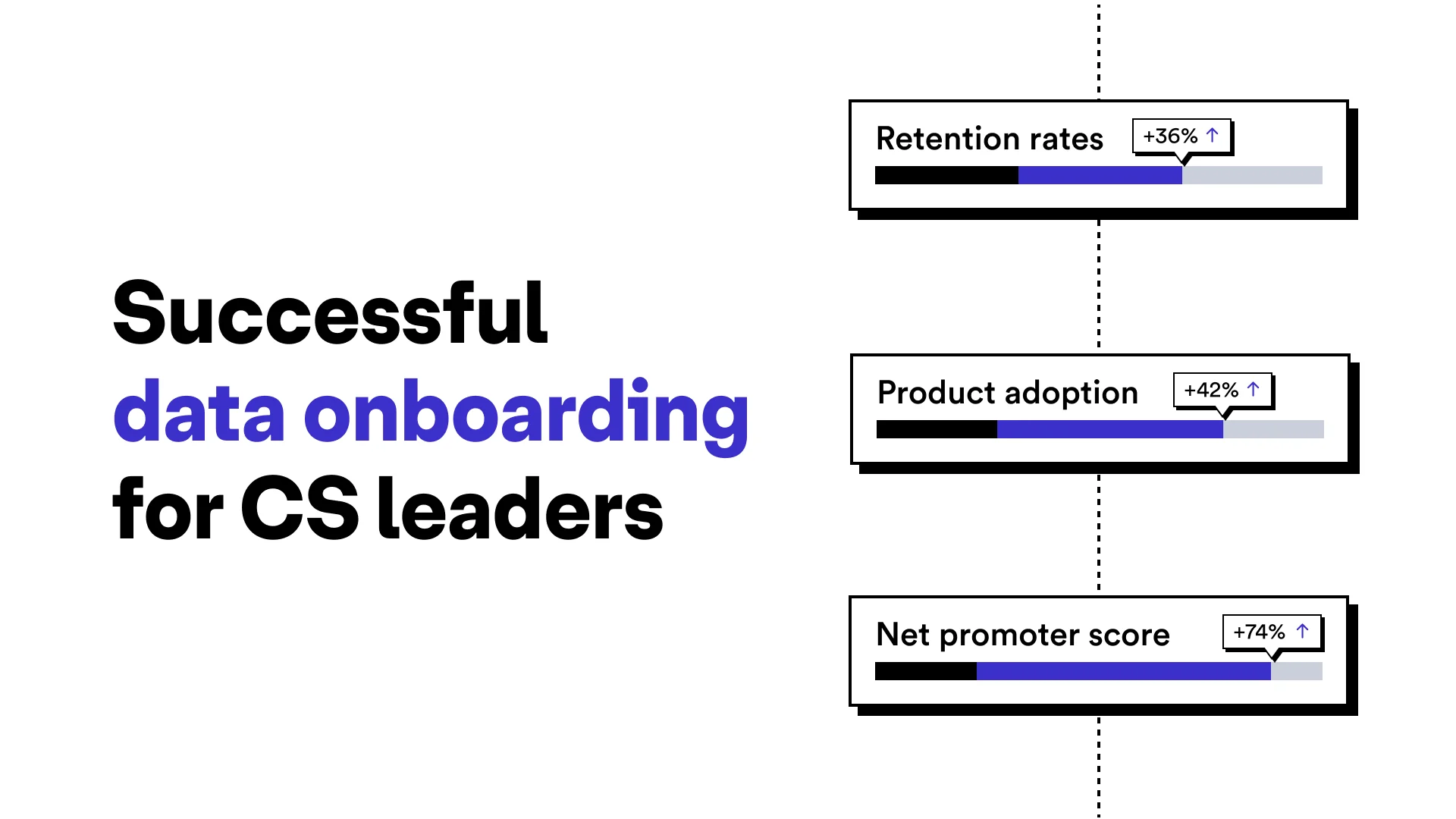
There's a lot of money to be made in focusing on customer retention. For software companies, it's impossible to prioritize retention without taking a good hard look at just how simple it is for users to import their critical data during the data onboarding process.
That's why a quality data importer is worth considering when it comes to customer retention and the overall customer experience. Consider that US companies lose $136 billion per year due to customers switching, and increasing customer retention rates by 5% has the power to lift profits by 25% to 75%.
Accelerate your business with data
Join a free demo to discover why Flatfile is the fastest way to collect, onboard and migrate data
Top data importer features to consider
Data importer features can number in the dozens. When considering implementing a pre-built data importer for your software, you must first check for the essential features.
You're looking for something that fits naturally within your product, that will be easy for customers to use, and that will drastically reduce the time it takes for data to be useful.
Let's take a look at the five must-have features below.
Data importer feature 1: Data parsing
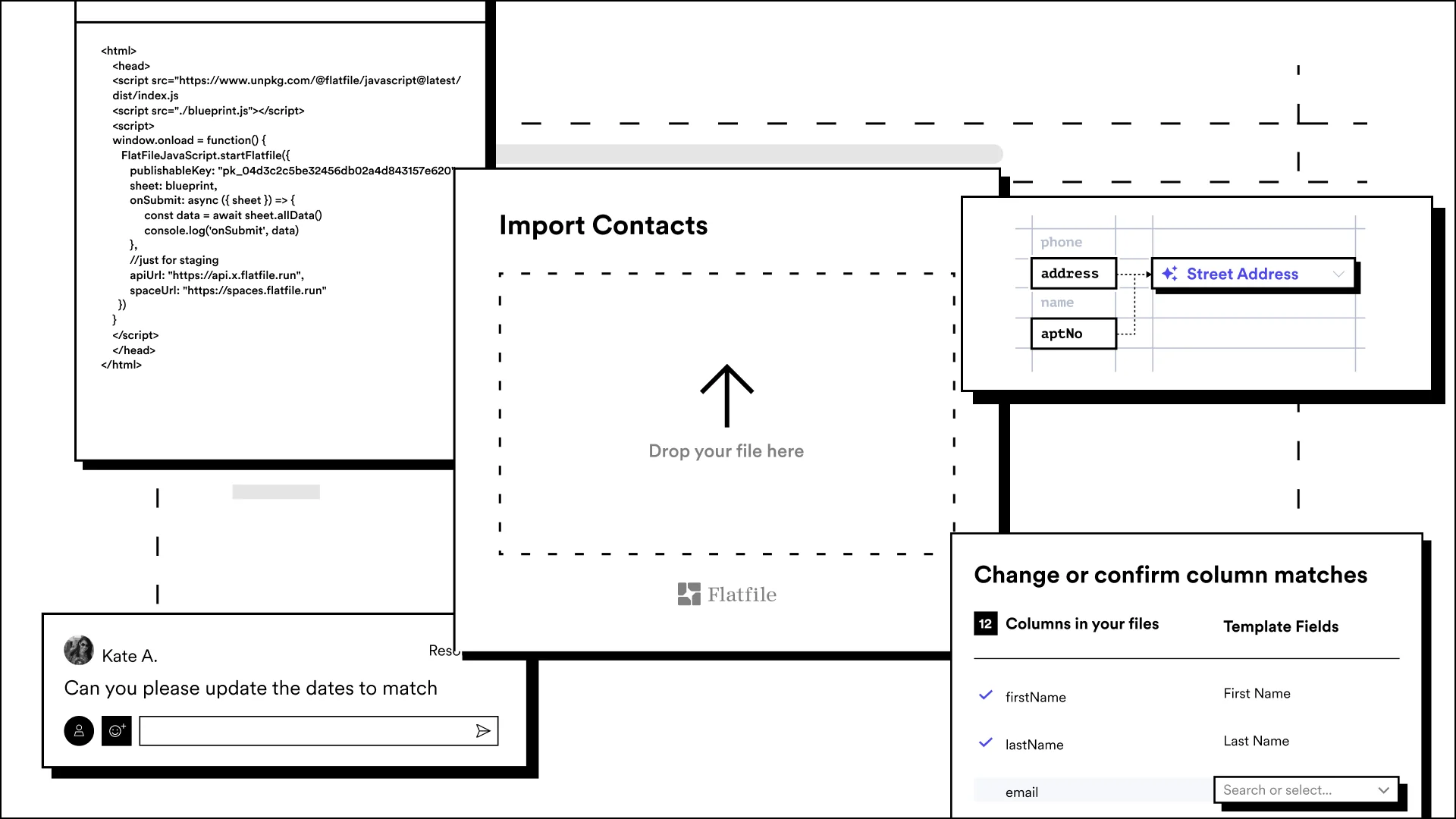
Data parsing is the process of aggregating information (in a file) and breaking it into discrete parts. Essentially, data parsing means the separation of data. The Flatfile Data Exchange Platform not only handles data parsing, but offers intelligent parsing, so a user doesn't have to explicitly define how a file has been aggregated, such as, "This is a UTF-8 encoded CSV." Instead, the encoding is auto-detected from the file.
You'll want to look for a data parsing feature that not only provides the technicalities of going from a file to an array of discrete data but also streamlines this process for your customers.
Data importer feature 2: Data mapping
Data mapping and matching often get used interchangeably, but either way, this usually refers to taking the previously unknown data that you started with and matching it to a known target.
It's an absolute requirement that your data importer do this very well. A good example is when you need to configure your data importer to accept contacts. Let's say that one of the fields is "email." The customer might choose a file where the field is labeled "email address."
If you don't have data mapping in the product experience, that example import will fail because "email address" does not equal "email," so the customer can't complete the import.
Data importer feature 3: Data structuring
Most product teams have an application database and an API, and they want to make sure the data can flow seamlessly into the database. How you get data into your system matters because you want to ensure it's labeled appropriately. APIs expect a specific format of data and will fail otherwise.
A data importer should be flexible and be able to plug data into your application or database in any way you best accept it. Flatfile's data onboarding platform offers a variety of ways to structure data that has been uploaded, mapped, and validated by users, meaning it can fit right into your preferred data flow.
Data importer feature 4: Data validation
Another important feature for a data importer is data validation, which checks if the data matches an expected format or value.
Having this feature in place prevents issues from occurring down the line. For example, if special characters can't be used within a certain template or other feature, then you don't want customers to be able to import them. Otherwise, they'll be frustrated when an error message pops up during use that should have appeared during the import stage. Without data validation, your customers might end up having to remove and re-upload data. That can lead to frustration, which, of course, leads to churn.
Data importer feature 5: Data transformation
Data transformation is another key feature. Data transformation means making changes to data as it flows into the system to meet an expected or desired value. Rather than sending data back to users with an error message, data transformation can make small, systematic tweaks to make data more usable. For example, when transferring a task list, prioritization data could be transformed into a different value, such as numbers instead of labels or numbers that get rounded up.
The data importer you choose should include all of these features and seamlessly integrate with your product. When it's time to choose a data import solution, your goal is to save internal engineering resources and wow customers with an amazing data import experience.
Data onboarding should be fast and painless
Our free in-depth guide will help you address data onboarding challenges and help new customers become customers for life.
Editor's note: This post was originally published in 2020 and has been updated for comprehensiveness.
Eric Crane
Co-Founder & COO
Share to