Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
The ultimate introduction to data mapping

Anne Bonner
Writer
Share to

Data mapping is an essential data management process that will help you integrate, transform and use your data effectively.
Imagine you're in charge of a company's data strategy. You've got data coming at you from all corners: Sales figures, customer profiles, inventory updates, you name it. Your job is to make sure all the data hangs together across systems and is accurate and consistent.
Fortunately, data mapping can help organize that chaos into a structured, meaningful format.
It's all about connecting the dots between different data sources so they speak the same language and play well together. For example, if one system calls a customer's age "Age" and another system labels it "Birth Year," data mapping is the bridge that says, "Hey, these are talking about the same thing!"
Interestingly, the systems that capture, generate or store data have different and unique requirements. It's not just that there’s a lot of information that needs to reference the same thing (the data in the “Age” column in one system can simply populate an “Age” column in a different system), but that there are usually nuances in how data is stored.
Spend 70% less time onboarding data
Join a free demo to learn how to collect, map, validate, transform and convert the data that powers your business. Faster.
For example, if one system calls a customer's age "Age" and another system has a "Birth Year" label, simple mapping would just map "age" to "birth year," and the values wouldn't change. But if someone is 52, they weren't born in '52! That's where transformations come in, and it's where mapping can become very powerful. Taking "Age" (field) and 52 (value) and creating a mapping rule that subtracts the age value from the present year will give you a value of 1972, which can be put into the "Birth Year" field.
You're about to get a lot more information about data mapping! Here are the key topics this article covers:
Want to learn how you can conquer data mapping issues and accelerate your data workflow? Schedule a free demo now for a personalized look into how Flatfile can solve your data challenges.
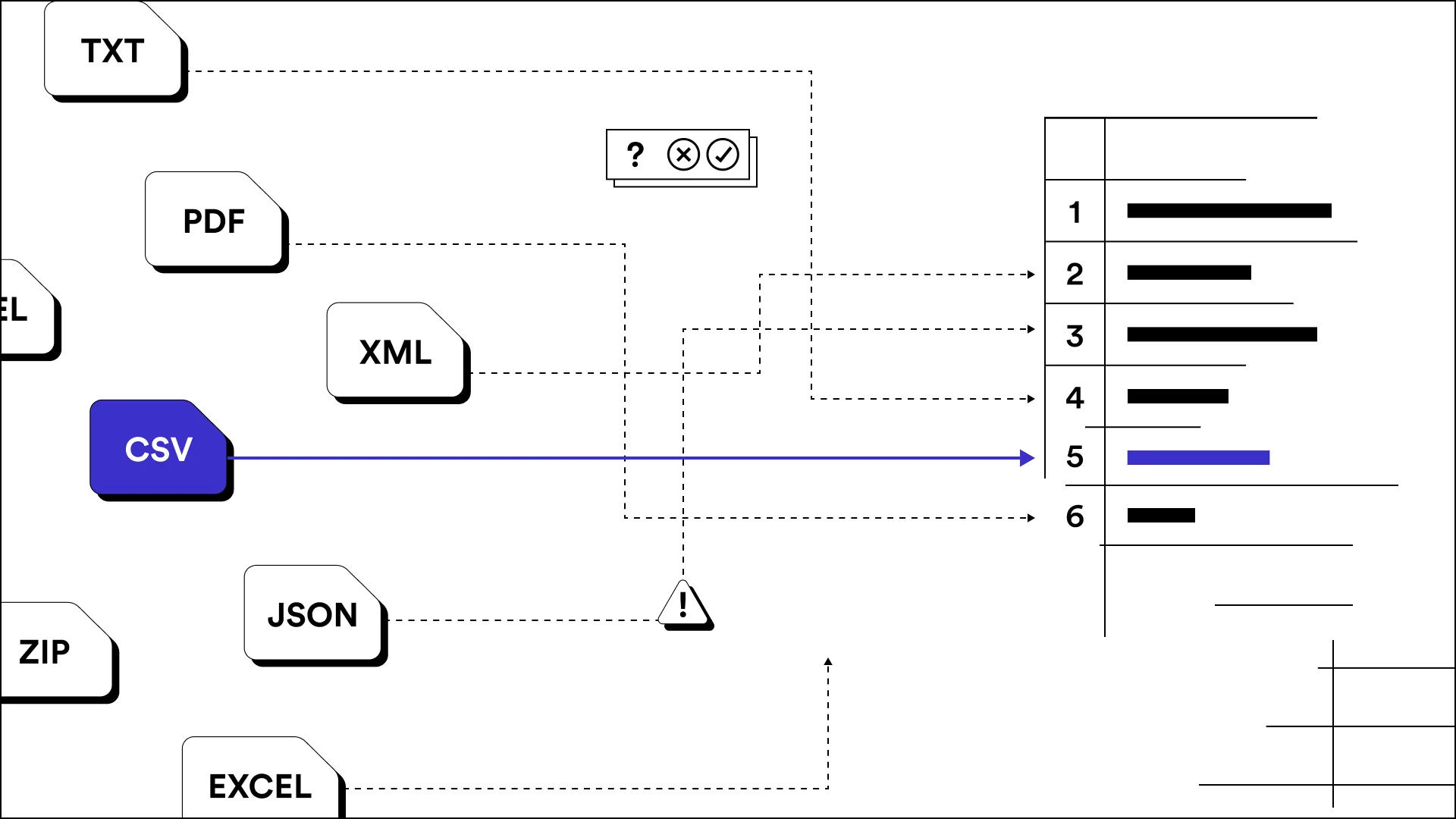
What is data mapping?
Data mapping is the process of associating data elements (or attributes) from one data source to another. It defines how data in one format corresponds or relates to data in another format and involves mapping data structures, fields and relationships between source and target data sets. This process helps with things like data integration, migration, transformation and analysis. It’s commonly used in various fields, like data integration, data migration and data transformation.
For a really simple understanding of what data mapping does, picture a child's shape-sorting set with blocks shaped like triangles, squares and circles and a cylinder with cutout holes for each specific shape. If the shapes represent your data and the cylinder is the destination where those shapes need to go, data mapping is how you would define which blocks go into which cutouts.

Image by Nina Garman from Pixabay
Key components of data mapping
Source data: This just refers to the data before you do any mapping or importing. It can be stored in databases, files, APIs or other data repositories. Understanding the source data's structure, format and content is critical for effective mapping.
Target data: This is where the data needs to end up. The target, or destination, data is where the mapped data will be loaded or transformed. This could be another database, data warehouse, application or platform.
Data elements: This is basically the fields and their types. You have the schema of the source and the schema of the target, and an important part of data mapping is identifying (and mapping) specific elements, or attributes, between your source and target data sets.
Mapping rules: These answer the question, “What needs to happen?” Mapping rules define how each of the data elements from the source maps to a corresponding element in the target. These rules cover data transformations, data validations, default values and the business logic applied during the mapping process.
Data transformations: This is where the magic happens! Data mapping might include tasks (transformations) that convert, clean or aggregate data as it moves from the source to the target. Transformation rules specify how data should be modified, formatted or calculated during the data mapping process.
Data onboarding should be fast and painless
Our free in-depth guide will help you address data onboarding challenges and help new customers become customers for life.
There are a few basic ways you can tackle data mapping:
Manual mapping: Totally hands-on. Here, people meticulously match data elements based on their understanding.
Automated mapping: Automatic. In this approach, algorithms and tools do the heavy lifting, which is really useful for large-scale projects.
Semi-automated mapping: You guessed it – teamwork! Here, people and machines team up. Machines suggest matches based on preset rules, and people fine-tune the details.
Each has its perks, and the ideal approach really depends on what you need to accomplish.
Why is data mapping important?
Data mapping is incredibly important for lots of reasons, including:
Data integration and consolidation: Would it help your decision-making if you could combine information from different datasets? With data mapping, you can combine datasets for better insights and improved efficiency. Data mapping will let you integrate data from multiple sources (like databases, applications and APIs) into a coherent data model. It can help you consolidate data from disparate systems, helping create a single source of truth. With accurate data mappings, you can avoid data silos and ensure that all relevant data is accessible and usable across the organization.
Data migration and system upgrades: Have you ever had to move data from an old system to a new one? During data migration projects, data mapping helps you smoothly transfer data from an old system to new platforms or applications. It helps maintain data integrity, consistency, and compatibility between the old and new (source and target) environments and it helps map old data structures to new ones, which will help to ensure data compatibility and integrity. Data mapping reduces the risk of data loss or corruption, preserving continuity and your business operations.
Data transformation and cleaning: Data mapping is also essential for tasks like data cleaning and standardization! It facilitates data transformation processes by defining how data should be converted, formatted and manipulated to meet specific requirements. It allows organizations to define transformation rules and mappings to convert raw data into a clean, consistent, usable format. By mapping data elements and applying transformation logic, companies can improve data quality and reliability.
Business intelligence and analytics: Any interest in getting the most accurate information possible from your data? Mapping data elements allows organizations to assess and improve data quality. By identifying inconsistencies, redundancies and errors, organizations can implement corrective measures to enhance data accuracy and consistency. Effective data mapping is critical for business intelligence and analytics initiatives.
Data governance and compliance: Data mapping contributes to data governance practices by establishing clear data lineage, metadata management, and data ownership. It supports regulatory compliance efforts by ensuring that data mappings adhere to industry standards, privacy regulations, and data security protocols. With documented data mappings and governance frameworks, organizations can maintain data integrity, transparency, and accountability across their data assets.
System interoperability and integration: Data mapping can also improve your workflows by helping you exchange data between different systems. Data mapping facilitates system interoperability by mapping data structures, formats and protocols between different software applications and platforms. Data mapping supports API integrations, data-sharing agreements and collaboration between internal and external stakeholders.
Decision-making and strategy: This is pretty obvious: By having a clear understanding of how data elements are mapped and transformed, you can make decisions that drive growth and innovation. You can analyze mapped data to identify trends, patterns and opportunities which will help you measure key metrics, track business performance, and assess the impact of your decisions.
How does data mapping work?
Data mapping works by establishing relationships and connections between data elements. The goal is to define how data should be transformed, converted or transferred from one format to another to ensure compatibility, accuracy and consistency.
Here's a basic overview of how data mapping works:
Identify source and target data sets: The first step in data mapping is to identify the source data set and target data set. The source might be a database, file, API response or any other data source and the target data set could be another database, data warehouse, application or analytics platform.
Define mapping requirements: Next, you need to determine the specific data elements that need to be mapped from the source to the target. This includes fields, columns or entities like customer names, product IDs, dates, etc. You should define the mapping requirements based on business rules, data integration goals, transformation logic and data quality standards.
Create data mapping rules: Once you've identified the source and target data sets and determined the requirements, you want to define specific data mapping rules that specify how each data element from the source maps to its corresponding element in the target. Mapping rules be simple one-to-one mappings where a source field directly corresponds to a target field (sometimes called "source-to-target mapping") or involve complex transformations, calculations or lookups.
Perform data transformation (if necessary): Data transformations can be tasks like data type conversions, data formatting, data cleaning (for example, removing duplicates and correcting errors), data aggregation and deriving new fields. If data transformations are necessary, apply your defined mapping rules to transform data as it moves from the source to the target.
Handle data mapping challenges: Things might not go perfectly right away! You’ll want to implement error handling mechanisms to identify and correct mapping errors or data validation failures to address challenges like handling discrepancies, resolving conflicts, managing data quality issues and ensuring consistency.
Validate and test data mapping: Validate the data mapping by comparing sample data from the source and target to ensure that mappings are accurate and producing the expected results. Conduct testing and validation procedures to verify data integrity, completeness and correctness after applying mapping rules and transformations.
Execute the process: Show time! Execute the data mapping process using appropriate tools, software or scripts that support data integration, ETL (Extract, Transform, Load), or data migration tasks. Make sure to monitor the data mapping process for performance, scalability and efficiency.
Document the details: Write it down. Document the data mapping details, including mapping rules, transformations, source-to-target mappings, data lineage, metadata and any relevant information for future reference and maintenance. Maintaining comprehensive documentation to support data governance, regulatory compliance and knowledge sharing is a good idea.
By following these steps and best practices, organizations can effectively implement data mapping processes that enable seamless data integration, transformation and migration while ensuring data quality, consistency and reliability.
Stop wasting money
Download this free report to discover the missing piece that will help you reduce data errors and maximize revenue opportunities.
Common data mapping techniques
Each data mapping technique has strengths and suits different data integration and transformation requirements. By understanding and leveraging these techniques effectively, organizations can ensure accurate and meaningful data mappings that drive success. Here are some of the most common data mapping techniques used today:
Schema mapping has to do with mapping the structure and attributes of data schemas or models between source and target systems. This includes mapping tables, columns, relationships and data types. Mapping fields like "First Name" and "Last Name" from one database schema to corresponding fields in another schema is an example of schema mapping.
Value mapping focuses on mapping actual data values or codes between systems. It can include translating codes or identifiers used in one system to their equivalents in another system, mapping country codes, product codes, customer IDs or currency values.
Relationship mapping maps relationships or associations between data entities, like customer orders, product categories, or employee hierarchies. For example, mapping the relationship between a "Customer" entity and an "Order" entity in different databases.
Transformation mapping defines the data transformations and business rules applied during data mapping, and that includes data conversions, calculations and validations.
Key challenges and considerations
Data mapping offers big benefits, but it isn’t foolproof. Some of the top challenges are:
Data quality: Ensuring data accuracy, completeness and consistency is a huge challenge in data mapping. Inaccurate or incomplete data can lead to mapping errors and unreliable insights.
Complex transformations: Handling complicated data transformations requires careful planning and execution.
Data security: Protecting sensitive data and ensuring data privacy during data mapping processes is critical for your customers, your reputation and to avoid data breaches and compliance violations.
Scalability: Scaling data mapping processes to handle large volumes of data and real-time data streams can be challenging and requires solid infrastructure and tools.
Version control: Make sure you maintain version control and documentationmto track changes, revisions and updates over time.
Common data mapping solutions
Companies often turn to data mapping solutions to address the challenges that come with DIY solutions. These tools and platforms offer features and capabilities that are tailored to meet diverse needs. Here are some widely used data mapping solutions:
ETL and ELT tools: ETL tools like Oracle Data Integrator, Apache Airflow and AWS Glue include data mapping capabilities as part of their data integration and processing workflows. These tools help organizations extract data from source systems, transform data using mapping rules and transformations, and load transformed data into target systems. They also support batch and real-time data processing, making them suitable for a wide range of data integration use cases.
Data integration solutions and iPaaS: These solutions enable end users to implement integrations between internal and external applications, services and data sources. Platforms like MuleSoft, Boomi, Frends and Celigo often offer features like graphical interfaces for designing data mappings, transformations and workflows. They also include connectors and adapters to easily connect to various data sources, applications, and systems.
Data file exchange: Even if your files come from tons of different sources in a wide variety of formats and need manual review, cleanup and validation before you can import them, a data file exchange solution will help you deal efficiently with all of the real-world data that you have. Platforms like Flatfile provide robust and even AI-enhanced data mapping capabilities as an integral part of their solutions.
Master data management (MDM) solutions: MDM solutions like Informatica iMDM and IBM InfoSphere MDM incorporate data mapping capabilities to manage and reconcile master data across multiple domains and systems. These solutions enable organizations to create and maintain a single, trusted view of master data entities by mapping and consolidating data from disparate sources.
Data quality tools: Data quality tools like Talend Data Quality and Oracle Data Quality provide data mapping features to ensure data accuracy, completeness and consistency. These tools allow users to define data mapping rules, perform data profiling and identify data quality issues during the mapping process and offer data cleaning, enrichment and deduplication capabilities.
Cloud data integration services: Cloud-based data integration services like Azure Data Factory and Google Cloud Dataflow offer data mapping solutions in a cloud-native environment. These services provide scalable and flexible data integration capabilities, including data mapping, transformation, orchestration, and scheduling. They use cloud infrastructure and services to handle big volumes of data and can support hybrid and multi-cloud data integration.
Open source data mapping tools: Open source data mapping tools like Apache Nifi and Pentaho Data Integration (Kettle) offer cost-effective solutions for designing and executing data mappings. These tools offer features like graphical interfaces, support for various data formats and protocols and community-driven development.
Best practices for data mapping
There are a number of data mapping best practices, but these are the most important ones to keep in mind:
Understand data requirements: Start by thoroughly understanding the requirements, business rules and objectives of your project.
Document mapping rules: Make sure you document mapping rules, transformations and metadata for transparency and consistency.
Data profiling: Conduct data profiling to analyze data quality, patterns and relationships before you map data elements.
Use automation tools: Use mapping tools and platforms that help you automate processes and reduce errors.
Data validation: Implement data validation checks to ensure accuracy.
Collaborate across teams: Foster collaboration between data teams, business stakeholders and IT teams to make sure your mapping efforts are aligned with business objectives.
Monitor and maintain: Continuously monitor data mappings, track data lineage and perform regular maintenance to address your needs as they evolve.
What happens if you don’t use data mapping?
If you don't use data mapping, you could face some pretty tough consequences. Here are just some potential outcomes:
Data inconsistency: Without data mapping, different systems might interpret data differently, leading to inconsistencies in data formats and naming conventions. This can result in data duplication, data errors and conflicting information.
Data silos: The absence of data mapping can contribute to the creation of data silos, where data is isolated and fragmented. This hinders data accessibility, collaboration and integration efforts, limiting your ability to derive insights.
Integration challenges: Integrating data from multiple sources is challenging without data mapping, and it can cause delays, inefficiencies and increased operational costs.
Data quality issues: Data mapping plays an important role in data quality assurance. Without proper mapping rules and transformations, data quality issues like duplicate records, inconsistent data formats and missing values can erode the reliability and accuracy of your data.
Misaligned business processes: Data mapping aligns data elements with business processes and objectives. Without mapping, there can be misalignment between data captured by systems and the information you need for decision-making, reporting and analytics.
Ineffective analytics: Data mapping is essential for creating structured, mapped data sets that are suitable for analytics and reporting. Without mapped data, analytics will almost certainly offer incomplete or inaccurate insights.
Compliance risks: Data mapping is crucial for ensuring data governance and regulatory compliance. Without mapping, you’ll probably struggle to track data lineage, maintain data documentation and enforce data privacy and security measures (which will expose you to compliance risks and penalties).
Operational inefficiencies: Without data mapping, tasks like data migration, data cleaning and data integration are usually inefficient and labor-intensive. This tends to lead to increased labor costs, data processing errors and operational bottlenecks.
Limited data integration flexibility: Data mapping offers flexibility in integrating data from diverse sources and systems. Without mapping, you can face limitations in adapting to changing data sources, business requirements and technological advancements.
Missed opportunities: Ultimately, not using data mapping will result in missed opportunities to leverage data as a strategic asset. You will probably fail to capitalize on data-driven insights, competitive advantages and growth opportunities.
By understanding the principles, techniques, challenges and best practices of data mapping, you’ll have an easier time staying competitive.
Mapping that’s magical
If all of this seems overwhelming, remember that you aren’t required to implement data mapping on your own! There are tools and solutions that can handle the data mapping process for you, and they often include powerful automations and AI-enhanced features that can streamline your entire data integration process. Flatfile, for example, can help you automatically generate rules for moving data between any two schemas and can easily map any two datasets. Trained on billions of user decisions, Flatfile’s mapping engine, for example, can convert data in seconds.
Flatfile's interface allows you to easily upload and map your data from various sources, including spreadsheets, CSV files, and more with just a few clicks, which will save you time and reduce the amount of manual work you need to do.
Flatfile also offers transformations that can detect and re-create nested records in a flattened file. If you have complex requirements, you can extend rule gen with custom logic by creating your own data logic that’s written in code. Plus, because it’s trained on years of data file imports, Flatfile’s AI-based column matching provides impressive accuracy and can remember what your customers do, putting everything where it belongs, automatically.
Using mapping choices recorded from 1.8 billion (and counting!) rows processed in Flatfile, we’ve trained a machine learning model that will work alongside the memory of your and your colleagues’ past selections to accurately predict more than 90% of matching actions. These mappings can reduce the number of actions you need to make.
You can also use smart rules that help you restructure your data as needed with recommendations from our AI model that’s pre-trained on hundreds of millions of user mapping decisions. With smart rules, you can automatically:
Assign values from one column to another: Flatfile can automatically alias source values to properties in the destination schema.
Merge multiple columns into one destination: When your destination model has a single property to assign values to but the source provides multiple destinations, Flatfile knows how to provide either
ArrayorConcat.Map data to nested records: For collections of values, Flatfile can turn columns into an array of nested objects (or inversely, turn a collection of objects into a flattened structure).
Use patterns to get parts of data from a source: Easily extract substrings from source data using exact pattern matching or use regular expressions for more complex needs.
Combine multiple values with a formula: Create text based values from multiple columns. For example, combine street, city, state and zip into a fully formatted address column.
Compute a final value from source data: Generate numerical values using your own custom formulas, utilizing multiple columns.
Apply a default value to a column: Apply default values wherever you’re missing data or have empty data.
Apply predefined changes to any field: Apply any standard text based transformations to your data such as case conversion, replacing special characters, or URL encoding.
You don’t need to know how to build robust data mapping capabilities yourself. Flatfile understands your data, not just your schema, and can help you go beyond simple mapping rules with AI that understands the meaning and context of your data. You can define what you want to do, and Flatfile will take care of the how. If you’re interested in learning more about how Flatfile can help you with your data mapping needs, you can get your API key and start mapping now, for free or reach out and get a custom demo for your specific use case.
Accelerate your business with data
Join a free demo to discover why Flatfile is the fastest way to collect, onboard and migrate data
Anne Bonner
Writer
Share to