Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
Building a seamless CSV import experience with Flatfile’s data onboarding platform

David Bonilla
Growth Marketer
Share to
CSV import as a process, is broken. Messy data, edge cases, encoding formats, error resolution, non-technical users: importing data into applications is a huge pain! Ingesting data has been long neglected as a software product experience, leading to customer frustration and wasted engineering cycles rebuilding what those users already expect to have. It’s a major distraction for product teams focused on building core differentiating features.
We’re going to look at problems with turning messy spreadsheets into structured product data, how it’s typically addressed, and how Flatfile’s data onboarding platform solves the technical and user experience challenges inherent in CSV, XLS, XLSX, or XML file imports:
Building vs buying a CSV Importer
Common problems with CSV import experiences
Introducing Flatfile’s data onboarding platform: The elegant import button for web apps
CSV import issues
Unclear Guidance
Maxing Browser Memory Limits
Vague Errors
Inefficient CSV Column-Mapping
Building a seamless CSV import experience with Flatfile’s data onboarding platform
Ready to get rid of CSV templates?
Building vs buying a CSV importer
If you’re a software developer and have built a CSV parser before, you know how frustrating it is to dedicate valuable engineering sprints to just one component of the customer onboarding. Building an entire CSV importer means addressing user experience and technical edge cases that result from involving humans in a highly technical ETL process. Trying to bake in more advanced functionality such as CSV validation, data normalization, column-matching, or even refining the interface itself results in developers building an entirely new product, before the first one is finished!
In most cases, developers attempt to work around this friction by providing users with FAQ documentation or tutorials (even in video!) that show them how to correctly use their data importer. Another popular “solution” is to provide pre-made CSV templates, and then ask users to manipulate their data to fit this data model prior to uploading data. However, doing this merely shifts the burden of work to the end user for a problem the product should solve. The last thing customers want - especially as a new prospect - is to sift through lengthy CSV import documentation or even watch video tutorials to import a simple spreadsheet.
It shouldn't be your users' job to figure out why your CSV importer isn't working.
Ultimately, customers rely on your product to extract value from it. Asking them to do extra work - whether it be using a spreadsheet template, watching a video, or reading a support article - before they’ve even seen your application working with that data is detrimental to their assessment of your product’s value.
Moreso, investing development sprints to fix an outdated data importer, or worse, building a CSV importer from scratch is now a pain of the past. Today, we’d like to plug Flatfile’s data onboarding platform, which allows engineering and product teams to revamp their entire data import flows not in weeks or months, but in minutes. Did we mention you’d save thousands of dollars in development costs?
Common problems with CSV import experiences
Importing CSV data is often one of the first interactions users have with a software application, especially “empty box” products. Unfortunately, there are too many ways that this data import experience can cause customer frustration, or worse, churn.
For users, an inefficient importer experience will cause them to question the value of the product itself.
“If the app can’t import my data easily now, what's going to happen once my data’s finally uploaded?”
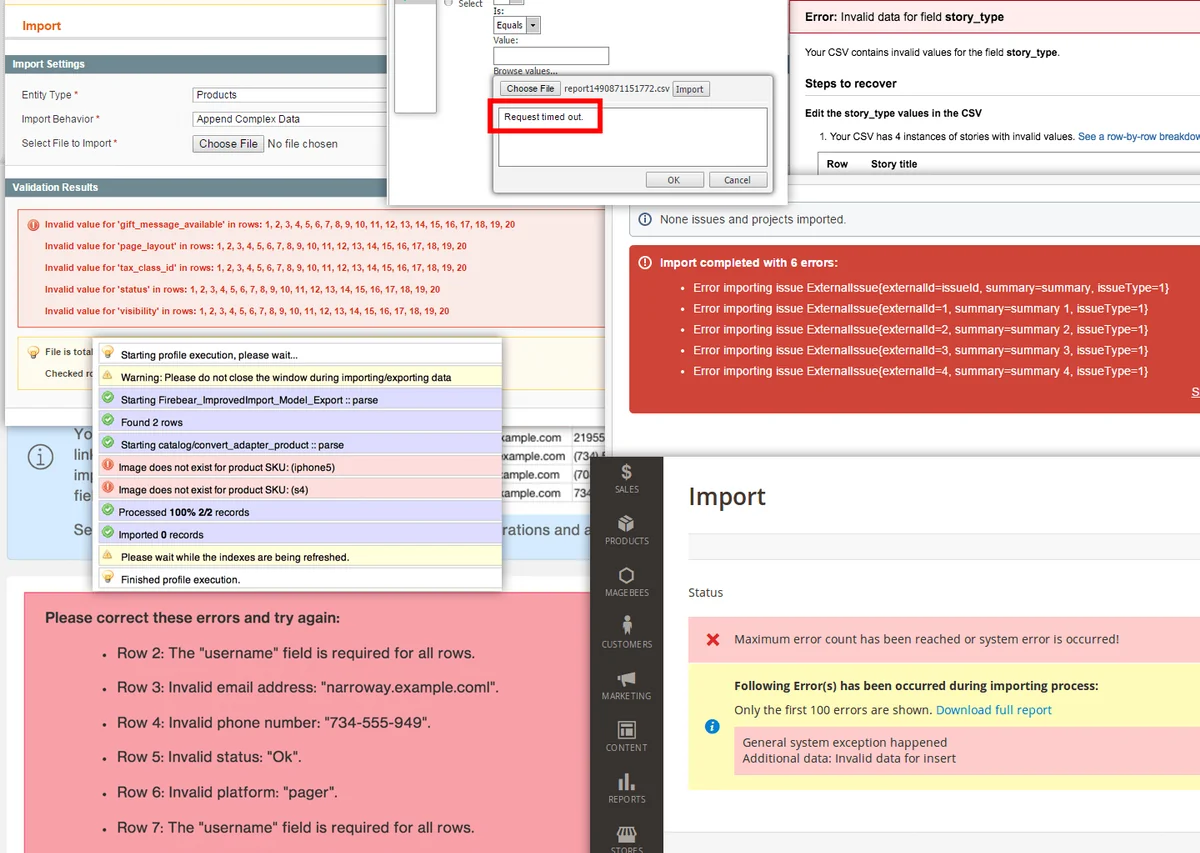
Your customers shouldn’t have to battle with these kind of CSV import errors (Source: Flatfile)
In addition to frustrating end-users, an inefficient CSV importer strains internal team resources. Not only have you invested significant engineering time trying to build what is essentially a second product for your application, now you’re spending time dealing with:
Emails and support tickets from frustrated customers who can’t import their spreadsheets into your system.
Import errors, which your team has to manually clean in your database backend before it’s usable in your product.
A never-ending string of data quality problems, due to lack of data normalization.
This is generally not a good position to be in as a data-driven product. Users expect a seamless customer onboarding experience; their goal after converting, is really just to import their data. You of course, really want them as a customer. To make sure you meet expectations, your internal team will handle the manual work of formatting and cleaning imported data for those customers. Congratulations on your new role as a data janitor.
What’s worse, all that effort you spent building your CSV importer could have been dedicated to building differentiating product features that move you forward in the market.
Digsy.ai shared their experience with handling data imports for their real-estate CRM product prior to integrating Flatfile’s data onboarding platform. Not only was the team strained on resources from building and maintaining a proprietary data importer, Digsy’s engineers spent ten or more hours per new user cleaning up and formatting incoming customer data. Occasionally, these users would churn, rendering all that work fruitless.
Thankfully, there's an out-the-box CSV importer that can do all this on its own, and with just a few lines of code.
Introducing Flatfile’s data onboarding platform: The elegant import button for web apps
We call it Flatfile’s data onboarding platform, and it was born out of frustration from continuously re-building CSV importers, parsers, and uploaders. Flatfile provides data normalization, CSV auto-column matching, CSV validation, and a modernized UI component with a few lines of JavaScript. Many of our customers implement Flatfile in as little as a day: a massive improvement over 3-4 engineering sprints with continuous maintenance tacked on.

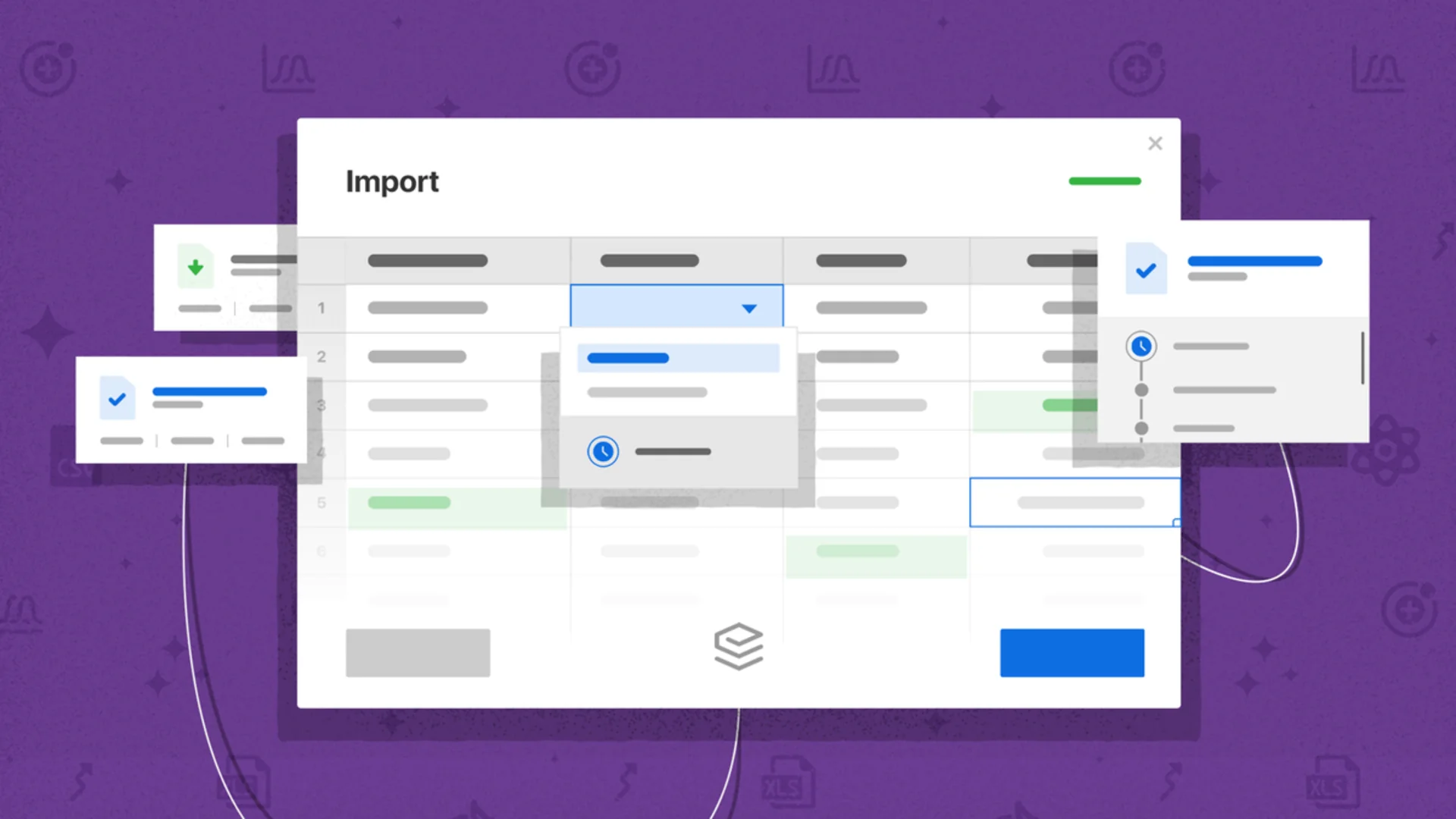
An illustration of some of the more frustrating CSV import experiences users have and how Flatfile’s data onboarding platform fixes them. (Source: Flatfile)
Let’s look at issues associated with traditional CSV import experiences and how Flatfile’s data onboarding platform addresses them.
CSV import issue #1: Unclear guidance
Users tend to struggle with CSV imports, and usually have questions before the CSV is even uploaded. Here are questions users may ask during an import:
Can I upload XLS, XLSX, or XML files?
What is UTF-8 encoding?
What if my file is 9.7 MB?
Is it a problem if my file has special characters in column headers?
What happens if my spreadsheet columns don’t match the required fields?
How do I fix my data? Do I need to save a duplicate CSV and upload that file instead?
Unless your users spend a lot of time exporting and importing spreadsheets, they’re not going to think about these situations until the moment they import their data.
It shouldn’t be up to your users to read through intimidating data import documentation or watch a 15-minute tutorial on how to import spreadsheets into your product. Surprisingly, developers aren't spared either! Although engineers understand the complexities of importing data into an advanced system (like Microsoft Azure), there is still an exhaustive amount of content they need to ingest before their first import even happens.

A highly technical product like Microsoft Azure attempts to reasonably present developers with extensive documentation for importing user data. (Source: Microsoft Azure)
Your product experience should make it simple to import CSV data without requiring users to become data scientists. The same goes for the technical understanding required to build a CSV importer to begin with, a goal we’ve dedicated reaching with Flatfile’s data onboarding platform.
Here’s an example of a simplified CSV import solution for a CRM from Flatfile’s data onboarding platform, created in less than an hour complete with complex data validation.
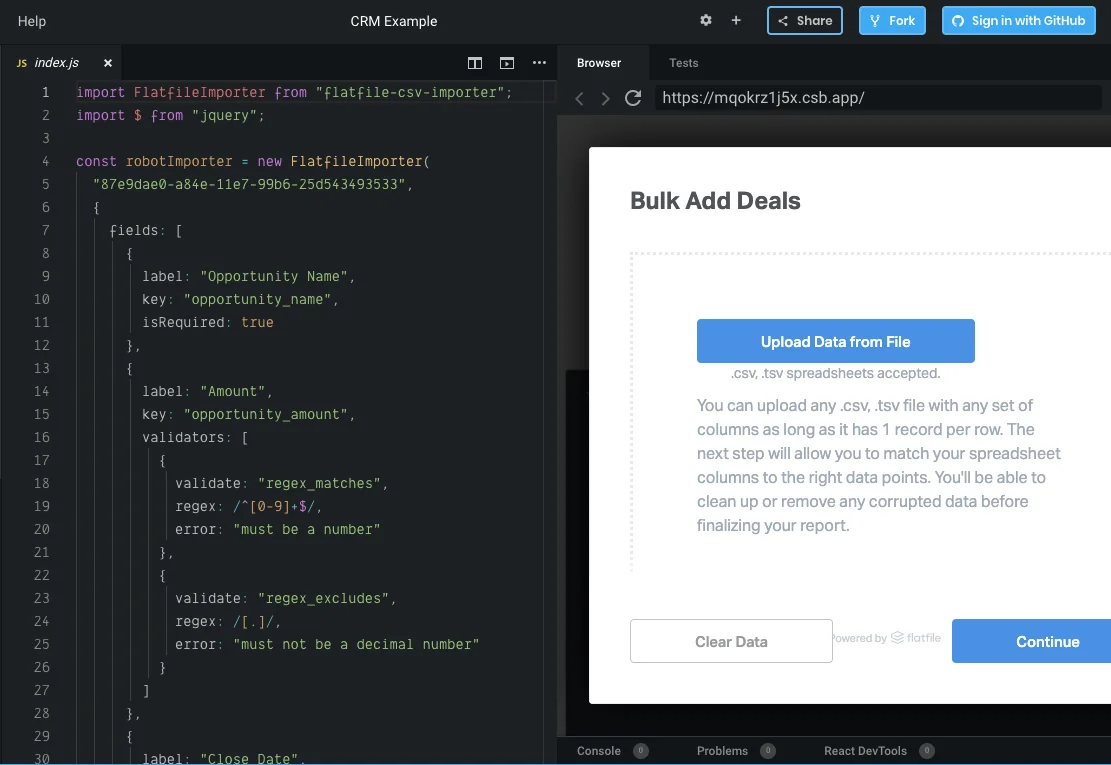
A demo of how Flatfile’s data onboarding platform helps software engineers quickly build a data importer with a few lines of JavaScript. (Source: Flatfile)
Flatfile’s data onboarding platform is standardized, responsive, and customizable to specific branding needs. With Flatfile, users will instantly know to:
Import their data using a CSV or XLS.
Match their spreadsheet columns in the next step, (if Flatfile’s data onboarding platform 95% fuzzy-matching doesn’t catch it the first time.)
Click “Continue” to begin their data upload.
There’s no need to overwhelm the user with warnings about file encoding, incorrect date formats, or what fields are required. Flatfile’s data onboarding platform solely focuses on importing CSV data from the user, and making it a delightful experience during this first touchpoint. Mapping columns and validating data will be completed at a later stage once the importer has matched the spreadsheet header columns using human-in-the-loop machine learning.
Flatfile’s data onboarding platform JS configuration allows data models to be replicated in minutes instead of weeks. The label matches a CSVs column name, and the key is how you’d like the imported data to be saved in the JSON output. Flatfile’s data onboarding platform also provides powerful validation options to work with any data model, and supports regex, data normalization, and server callbacks for those unique validation use-cases.
Once the data model has been built into the JavaScript config, all that needs to be done is to trigger the importer from within your product, typically by way of a button through a JavaScript call. If your application can execute JavaScript, you can integrate a truly modernized CSV importer, in minutes.
Not only is Flatfile’s data onboarding platform engineer-friendly, end-users will massively benefit from the modernized UI that guides them through a set of simple tasks. A sharp contrast from the spreadsheet import experience we’ve all grown accustomed to going through. It’s no wonder everyone from firefighters to city government officials rely on Flatfile’s data onboarding platform for data imports.
CSV import issue #2: Maxing browser memory limits
Let's assume that your users have successfully exported their data from another CRM and compiled it into a CSV file on their own. Then, they initiate an upload using your product’s data importer.
However, after watching the upload progress for what feels like an eternity, they receive the dreaded “Upload Failed” message. Something all too common with custom data importers.
It’s often why online forums and website support centers contain question-and-answer content like this one from the Go1 website:
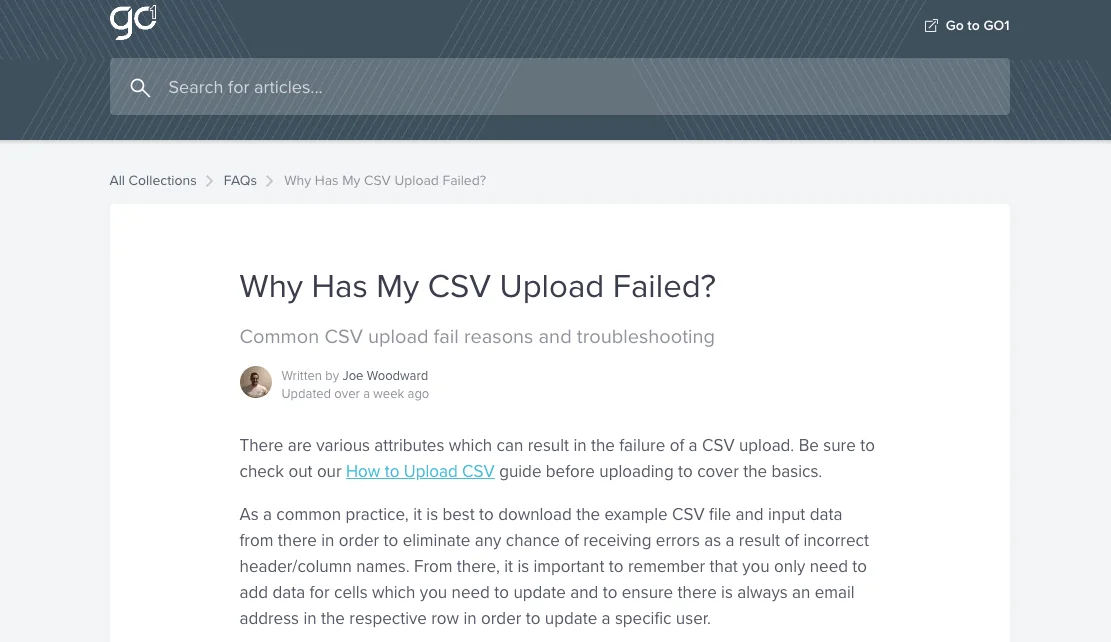
Go1’s support center answers the question “Why Has My CSV Upload Failed?”. (Source: Go1)
Or this one on the Nimble website:
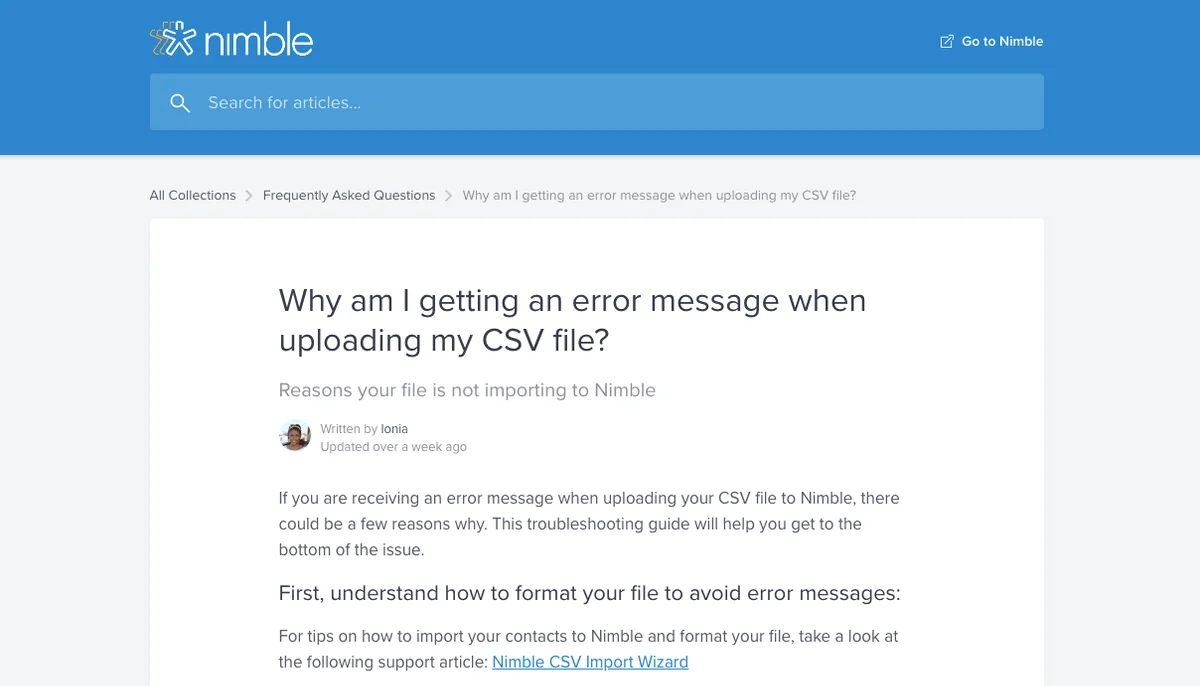
Nimble’s support center answers the question “Why am I getting an error message when uploading my CSV file?” (Source: Nimble)
Or this one from Nurture’s knowledge base:
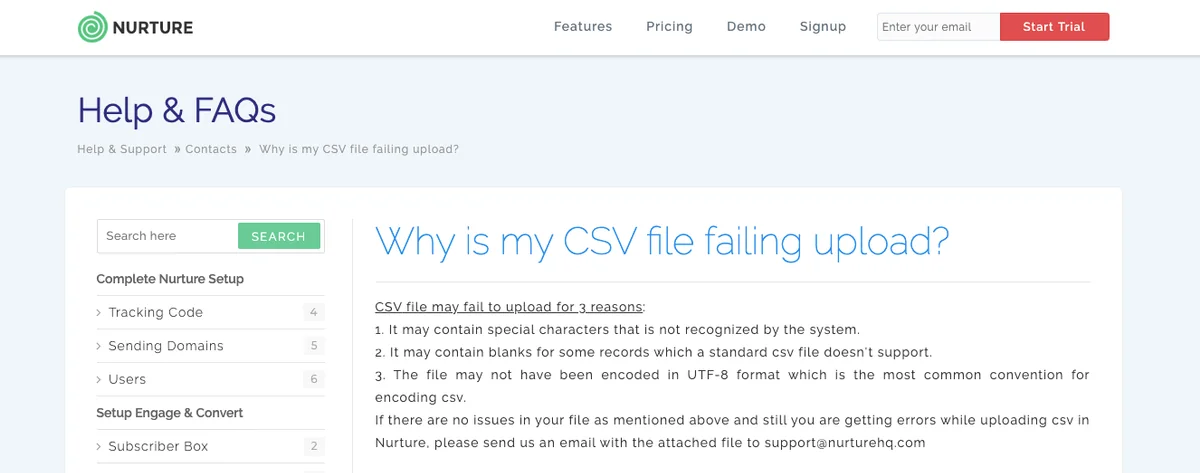
Nurture’s Help & FAQs answers the question “Why is my CSV file failing to load?”. (Source: Nurture)
Ultimately, this causes your customers to:
Worry about special characters in their CSV files.
In the case of Nurture, email your team over import issues, ultimately placing additional strain on your support team.
Download and use a spreadsheet template, since their column headers are ‘incorrect’.
With Flatfile’s data onboarding platform, you and your users won’t have to worry about things like file sizes or formats causing problems during import. Flatfile’s data onboarding platform helps you manage imported data via the browser or through a server-side process, enabling you to split and upload large CSV and Excel files without dropping imported data.
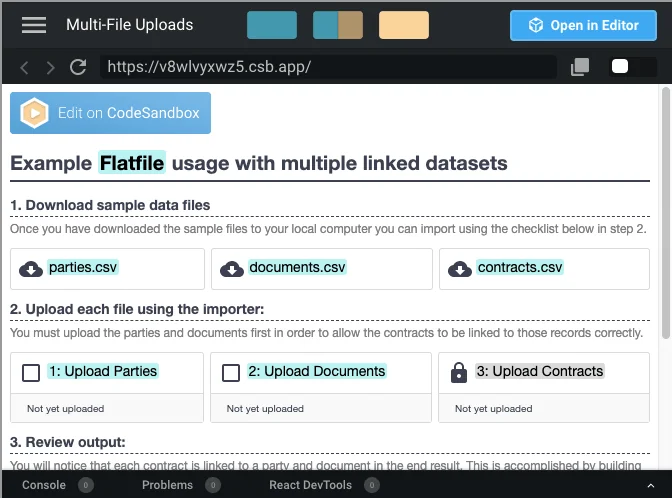
A Flatfile demo that shows how you can reliably split and import data from multiple files. (Source: Flatfile)
Flatfile allows users to import CSV data from multiple files intuitively, without dropping data or doing manual splitting. In this demo, users are allowed to upload CSV files containing three different sets of data. Not only will this help make their files more manageable, but it’ll make it much easier for your product team to ingest and organize customer data on your backend into a consistent structure.
CSV import issue #3: Vague errors
It’s not just confusing upload instructions or stalled imports that are going to give your users a headache.
Vague error messages don’t provide enough context for users to confidently repair their issues prior to uploading their data. Without specific explanation of the problem, your users are going to be stuck working through every possible fix until they find one that works (if any).
Take this reported issue with Jira, which has a fully-fledged knowledge base article to help users with this issue:
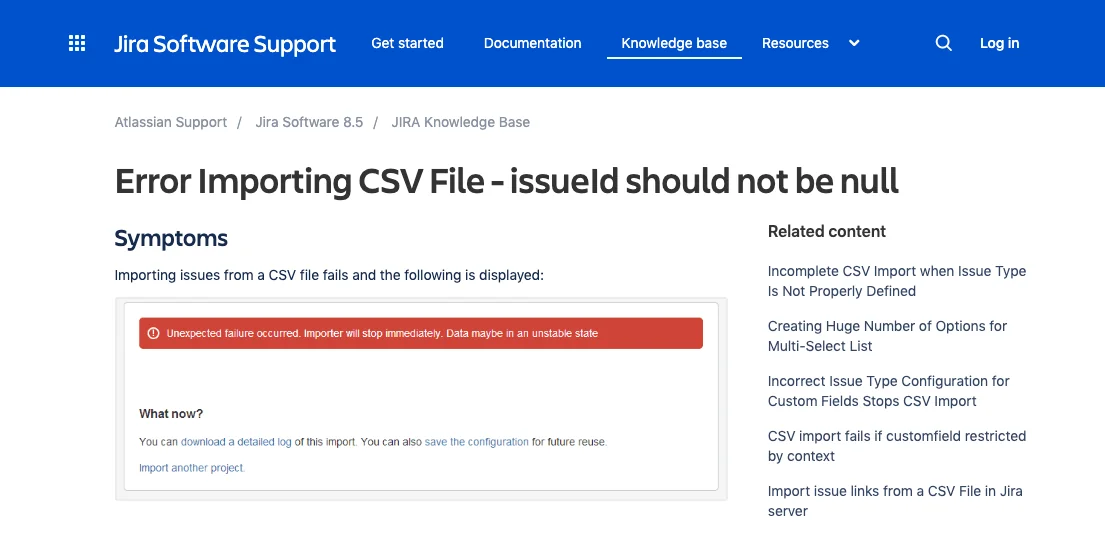
Jira knowledge base tries to help users that see the vague error message that reads “Unexpected failure occurred.” (Source: Jira)
The full error message reads: “Unexpected failure occurred. Importer will stop immediately. Data maybe in an unstable state.”
This isn’t particularly helpful. Not only does the user get a message calling their data “unstable”, but they also have to work through the issue from the vague details provided on this help page. The answer actually includes this as an explanation, which we can assume is only going to add to user frustration:
“This happens because the JIRA Importers Plugin tries to validate if the issues are valid for importing, and when the validation fails the error above is thrown.”
Essentially, the plugin is incapable of validating “Required” CSV fields outside of the ones it labels as required. Rather than transmit that message in the importer, users have to figure that out from this knowledge base article.
Customers shouldn’t have to think here. CSV importers should be designed — error messages and all — to make data import a quick and painless experience for users.
CSV import issue #4: Inefficient CSV column mapping
The next source of frustration often appears when poor column-matching functionality is in place.
As an example, let’s say that a Mailchimp user wants to load as many contact details into the email marketing software as they can. After all, it might be useful to have their business title or phone number on hand for future list segmentation.
However, initializing the import results in some data being skipped or dropped entirely:
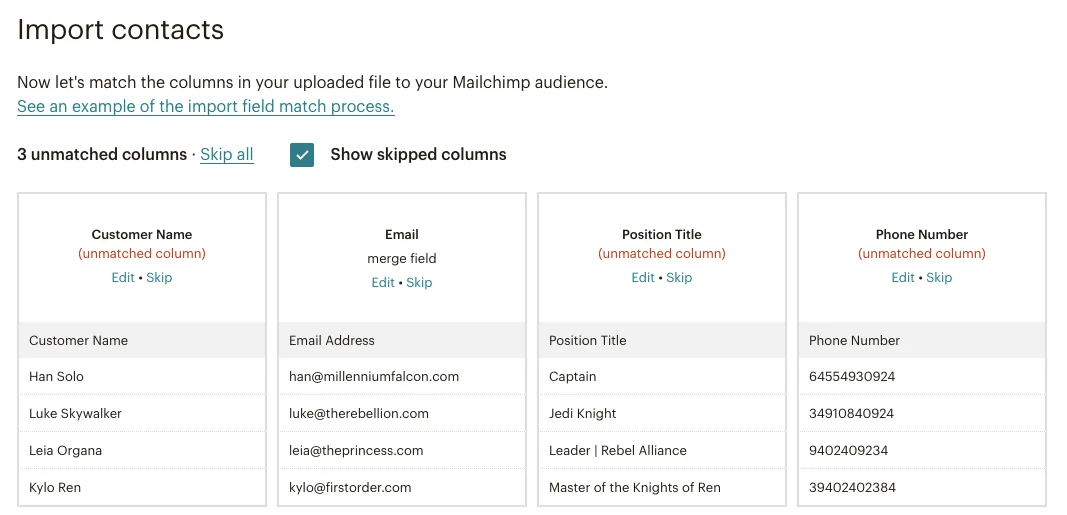
This is how Mailchimp’s CSV field-mapping system displays unmapped data. (Source: Mailchimp)
The app doesn’t recognize three of the four spreadsheet columns in our file. In order to keep the unmatched column data, the user has to go through each field and manually assign a matching label that Mailchimp accepts.
This is the case with many products that ingest user data, especially CRMs. Not all data will be used during an import, however the decision to allow custom field submissions in this case should be left to the user; rather than removing their data prematurely.
We know what you’re thinking: “Why not just provide a pre-built spreadsheet template?” However, this is hardly a solution to the problem and will only create more work and frustration for your users. Especially those that bring in thousands of rows of data, or have 40 column headers (yes, we’ve seen it!)
The data import experience is easier than ever: Start for free.
The problem here lies within the customer onboarding experience. Optimizing CSV import features within a product has been a difficult and expensive project to take on for product and engineering teams. That’s where Flatfile’s machine-learning, auto column-matching solution comes in handy.
Flatfile’s data onboarding platform automatically learns which incoming fields are matched to which columns from each of your users. This results in a ‘human in the loop’ machine-learning experience that is truly unique to your product’s data model. Flatfile’s data onboarding platform will automatically match imported CSV columns to your data model based on user inputs, and consistently learns over time.
The importer also caches column assignments regardless of session, so a user that uploads ten CSV files in a day will get most if not all of their columns matched automatically.
ClickUp, powered by Flatfile’s data onboarding platform, has leveraged human-in-the-loop for its productivity web app.
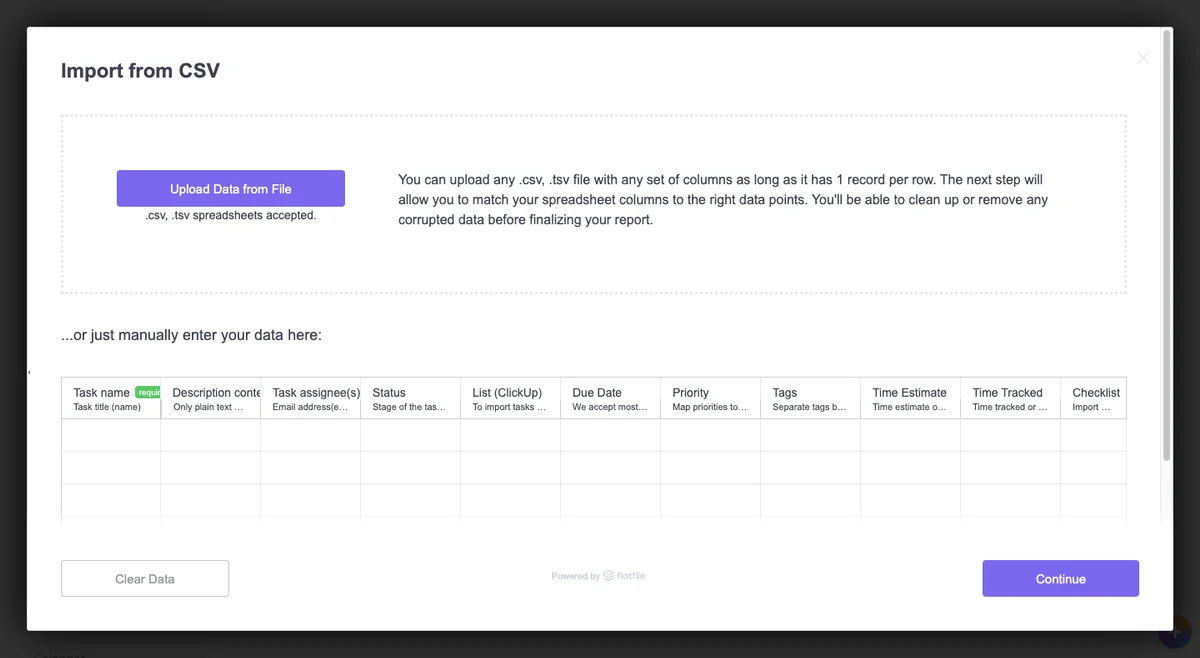
The main data import modal for users that want to import tasks and projects into ClickUp. (Source: ClickUp, powered by Flatfile’s data onboarding platform)
Flatfile’s data onboarding platform is designed to help users of all technical expertise. Instructions are clearly provided as to what the user can upload, and the fields required. In addition, Flatfile’s data onboarding platform manual data entry feature allows users to preview what sort of data can be imported into the productivity software. This helps users preserve as much data as possible, rather than realize too late that the data importer didn’t recognize their columns and dropped the data out without any notice.
Configuration flags extend Flatfile’s data onboarding platform functionality even further. For example, the allowCustom flag specifies whether you’d like users to add custom columns during the matching step. Using ClickUp as an example, one could add a column for “Billable”? As a boolean field to track whether a task is billable. Allowing users to place columns on the fly results in a shift of control not seen with legacy CSV importers - shaped by a product’s unique data model requirements.
Flatfile’s data onboarding platform column matching step:
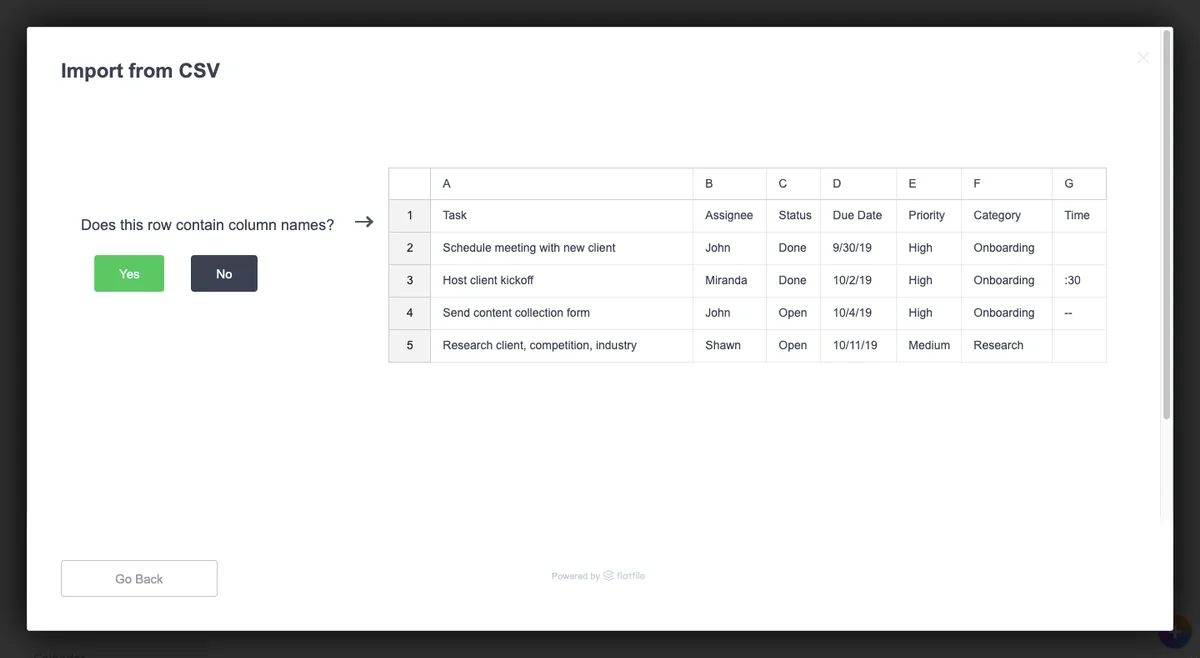
Flatfile’s data onboarding platform asks users to identify column names for accurate mapping. (Source: ClickUp)
This step asks users to indicate where their column names live. This way, the importer can more effectively match them with its own or add labels if they’re missing. Some CSV data may only contain values rather than column headers.
Next, users get a chance to confirm or reject Flatfile’s data onboarding platform column matching suggestions:
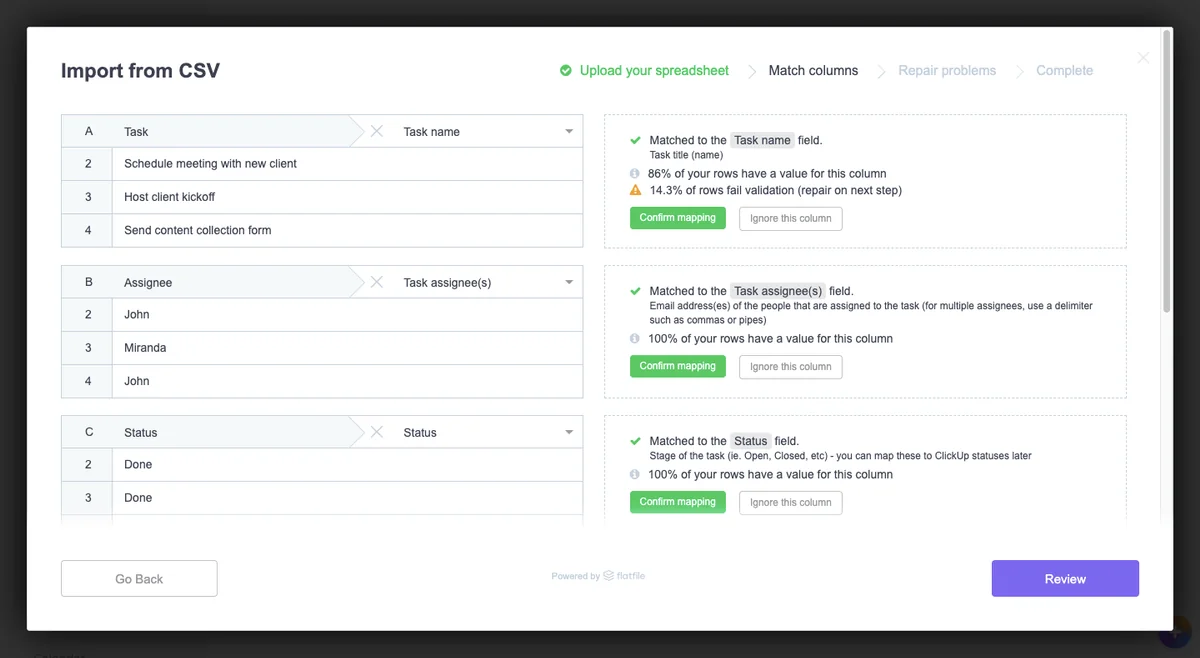
Flatfile’s data onboarding platform uses a machine-learning column-matching system to automatically map users’ imported data. (Source: ClickUp)
On the left, users will find the columns and values they’ve imported. The white tab to the right provides them with automated column matching within ClickUp’s data model. So, “Task” will become “Task name”, “Assignee” will become “Task assignee(s)”, “Status” remains as is and so on.
If one of the labels in the CSV doesn’t have any match at all, the importer calls attention to it like this:
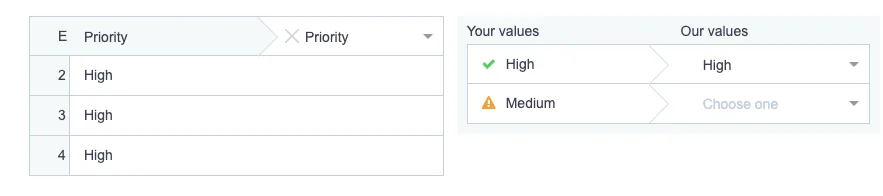
Flatfile Flatfile’s data onboarding platform calls attention to labels or CSV values that don’t have an exact match in a product. (Source: ClickUp)
In this example, the Priority response of “High” was detected. But “Medium” was not. However, there’s no need for the user to guess what the correct replacement should be. The importer provides relevant options like “Urgent”, “Normal” and “Low” to replace it with. No need to re-import their CSV, or change the value prior to importing the data.
Once all spreadsheet mappings have been resolved, the user can easily “Confirm Mapping” or discard the column altogether if it’s proven unnecessary.
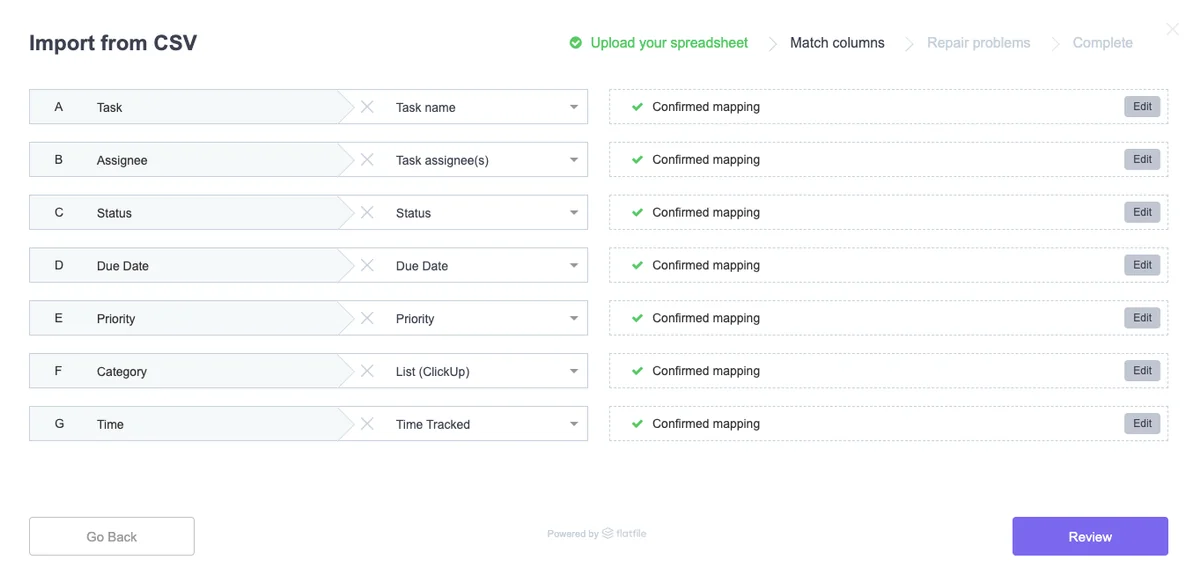
Users get a chance to confirm CSV labels and clean up their spreadsheet results before importing their data. (Source: ClickUp)
Finally, users get a chance to review any errors detected with their data:
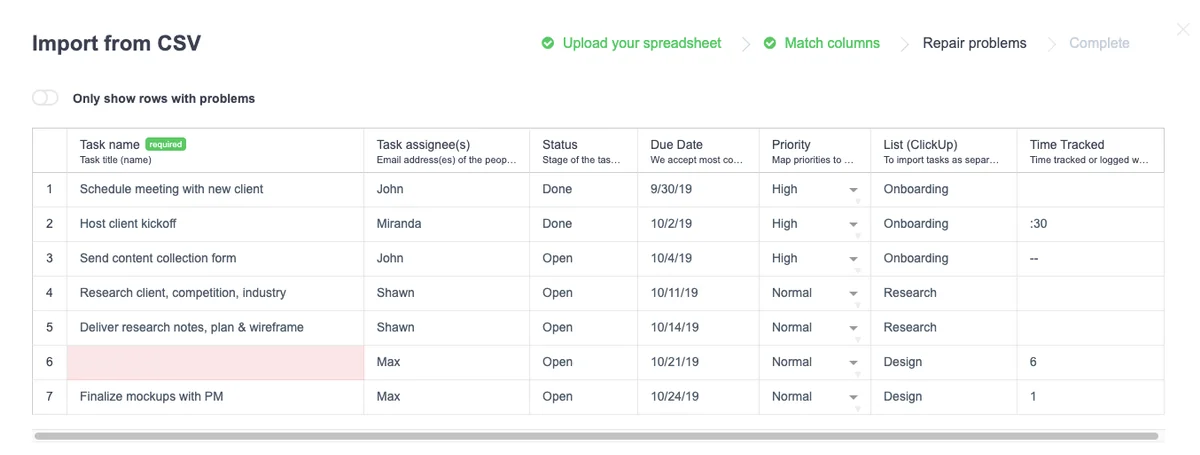
Validation errors detected in ClickUp’s data import appear in red. (Source: ClickUp)
In this ClickUp example, “Task Name” is triggered with the “isRequired: true” flag which requires users to submit data for that particular column. Whenever any validation fails in Flatfile’s data onboarding platform, you have full control over how error messages are displayed to the user - all inline within the importer.
The “Only show rows with problems” toggle in the left-hand corner makes error rows easy to spot and address quickly.
This keeps users from having to:
Review the original CSV file and fix errors before re-importing again.
Import the data and do the cleanup afterwards in the app.
How do you set up this system of column-mapping, CSV validation, and error detection? Flatfile’s data onboarding platform does most of the work for engineers.

There’s no need to build your data importer from-scratch with Flatfile’s data onboarding platform. (Source: Flatfile)
Flatfile’s data onboarding platform is configured via a JavaScript code snippet. Any labels, keys, or validation rules specified in this code will be reflected on the customer-facing data importer. This allows for complex validation on things like phone numbers or normalizing multiple date formats:
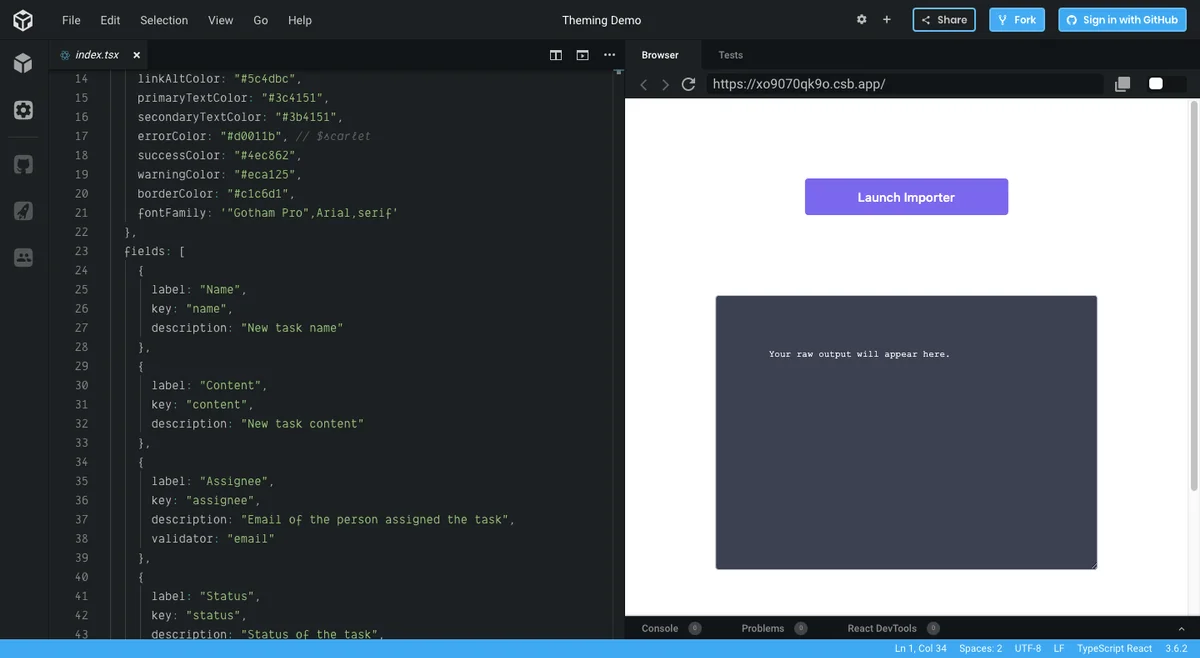
This Flatfile’s data onboarding platform demo provides the pre-written JavaScript code on the left and a sample of the importer output on the right. (Source: Flatfile)
Flatfile’s data onboarding platform is truly a turn-key CSV importer built for SaaS applications. The critical part to integrating Flatfile’s data onboarding platform is configuring the JS snippet to your product’s required data model. In other words, tell Flatfile’s data onboarding platforml what data needs to upload from users, what is the correct value, and whether you’d like them to add their own custom data.
Here’s a JS snippet you might use to customize Flatfile’s data onboarding platform for a basic contact list:
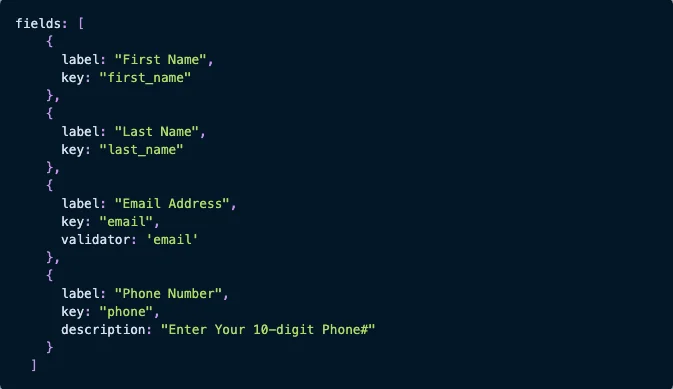
An example from Flatfile on how to configure the JavaScript with your own keys and labels for a basic contact list import. (Source: Flatfile)
You can then use validators to set strict rules for what can appear in the corresponding fields:
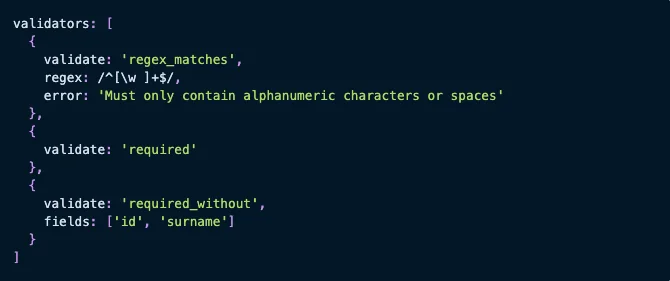
An example from Flatfile on how to code in complex validators including regex for CSV imports. (Source: Flatfile)
To recap:
It’s not easy building a CSV importer in-house. Integrating Flatfile’s data onboarding platform allows you to focus on differentiating core features unique to your product’s experience, knowing that the CSV import component is taken care of.
Building a seamless CSV import experience with the help of Flatfile’s data onboarding platform
One of the reasons we build SaaS products is so customers can effectively manage their businesses without the costly overhead of outsourcing to a third party, or the costly practice of trying to build everything themselves.
Importing data doesn’t need to be the reason for customer frustration or churn during customer data onboarding. It’s easy to see how users can be frustrated with the inconveniences of common CSV import errors. Take advantage of a tool like Flatfile’s data onboarding platform whose sole product focus is designing faster and more seamless data import experiences for your customers, partners, and vendors.
Stop wasting money
Download this free report to discover the missing piece that will help you reduce data errors and maximize revenue opportunities.
David Bonilla
Growth Marketer
Share to