Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
Data normalization: Manual vs. automatic

Anne Bonner
Writer
Share to
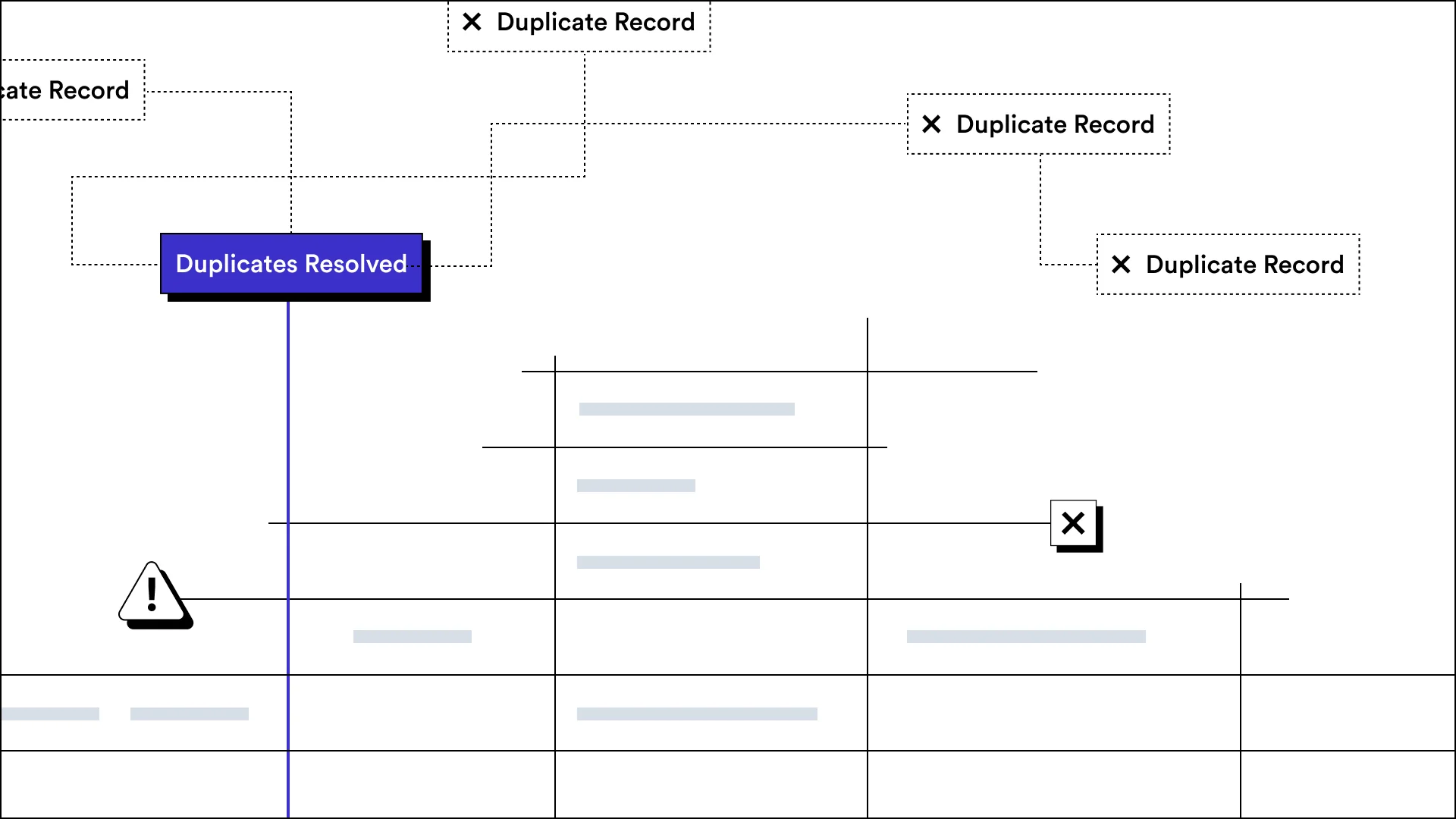
It's not easy to manage your data effectively, but techniques like data normalization can really help. Data in databases can reside in multiple tables, each representing different entities or concepts and redundancy is a common issue when the same data is stored in multiple places. Of course, redundancy can lead to inefficiency and an elevated risk of inconsistent data. Data normalization addresses these challenges by structuring data logically, eliminating redundancy, and maintaining relationships between entities.
Data normalization helps reduce redundant data and improve data integrity, and it's critical for customer data onboarding. Without proper data normalization, data quality issues are plentiful so customers can't get much use out of the data they import. The result is time spent updating data to where they can’t achieve what they want out of your platform. Of course, this inevitably could lead to customer churn.
With most data importers, building data normalization functionality is labor intensive. Thankfully, it can be done automatically instead of manually, so you no longer have to put customer experience at risk in order to save time.
Data onboarding should be fast and painless
Our free in-depth guide will help you address data onboarding challenges and help new customers become customers for life.
What are the goals of data normalization?
Eliminating data redundancy
Reducing duplicate data minimizes storage space and ensures consistency across the database.
Preventing data anomalies
Data anomalies such as insertion, update, and deletion anomalies can occur when data is not normalized. Normalization helps mitigate these risks.
Ensuring data integrity
By organizing data logically and enforcing rules, data integrity is preserved, and accuracy is maintained.
Want to learn how you can tackle data normalization and accelerate your data workflow? Schedule a free demo now for a personalized look into how Flatfile can solve your data challenges.
Data normalization helps reduce redundant data and improves data integrity. It's critical for customer data onboarding. Without proper data normalization, data quality issues are almost guaranteed, which means customers won't get much use out of the data they import. As a result, they spend too much of their available time updating data and are less likely to achieve the results promised by your platform. Of course, this often leads to customer churn.
With most data importers, building data normalization functionality is labor-intensive. Thankfully, it doesn't have to be. It can be done automatically, which means that you no longer have to put customer experience at risk to save time.
In this post, we dive into the definition of data normalization, why it matters, and your options when it comes to importing data, covering:
What is data normalization?
Why is data normalization important?
Do you always need to normalize data?
The two primary data normalization methods
What is data normalization?
There are lots of slightly varied definitions, but when it comes down to it, data normalization is about organizing data in a database so that internal teams can easily use the database for queries and analysis. Database normalization represents a systematic approach to composing tables to eliminate data redundancy and is a multi-step process that puts data into tabular form, removing the duplicate data from its relational tables.
Normalized databases make creating, updating, and deleting rows significantly easier while ensuring data consistency and decreasing redundancy.
Data normalization is especially important when importing data into a product, such as in customer data onboarding.
Why is data normalization important?
Is data normalization really important? Or is it okay to build a CSV importer or other data import experience without data normalization baked in?
Database normalization is important for a few key reasons:
Eliminating repeated data = more space and better performance:
Repeated data in any software system can cause major disruptions during subsequent transactions and requests. Once duplicates are eliminated, there's more space in the database. Not only is there additional space, but without duplicate data, systems will run smoother and faster.
Get the answers you need:
Once errors and redundant data are gone, the data is clean and can be organized more easily. Now that a company has organized data to work with, data analysis can happen much faster.
When it comes down to it, there has to be some form of logic with how your database is organized. If you have large sets of unorganized data, it goes to waste. It can't be merged, let alone properly utilized.
If a table is not properly normalized and has redundancies, it will not only eat up the extra memory space but also make it challenging to handle database updates.
Without data normalization, you ultimately cause problems for your customers when they try to utilize the data they've imported into your system. There can be endless data anomalies that make the database dtoo large and messy to be useful. An example of a data anomaly would be if you have an employee management system and you upload a CSV file of all employees with their managerial role written individually instead of being one form of data (role) that gets linked to the employee.
If the name of a specific role gets changed, it needs to be updated with every affected employee record instead of being changed once.
All in all, it's critical to normalize data: updates run faster, data insertion is faster, there are smaller tables, and data is more consistent. For these reasons, a fully normalized database is always worth achieving.
When it comes to importing data and data onboarding, a lack of data normalization leads to a never-ending string of data quality problems.
Do you always need to normalize data?
Is normalizing data always necessary? Though very rare, there can be cases where you don't need to normalize data. For example, you might not normalize data because your application is read-intensive, meaning that it predominantly reads databases rather than writes.
When an application is read-intensive, normalized data can complicate the queries and make the read times slower because the data is not duplicated, necessitating table joins.
Table joins can also make indexing slower, which again makes read times slower.
If your goal is data integrity and consistency, however, database normalization is a must!
Accelerate your business with data
Join a free demo to discover why Flatfile is the fastest way to collect, onboard and migrate data
The two primary data normalization methods
When most software engineers think of data normalization, they assume it's all manual work, but another option exists.
Manual data normalization
Building data normalization into your CSV importer is a lot of work. Since database normalization completely changes the way table schemas are designed, it's a tedious process to go through if it's not performed correctly. You need to ensure that
There are no repeating forms of data
Attributes are correctly dependent on their
Teams can put the burden of manual data normalization on customers and users and require them to fix all the data quality errors if a data importer doesn't have a data normalization feature. However, having customers update data after error messages pop up as they try to import data is a terrible customer experience.
To avoid this, companies too often put the responsibility on the customer who is importing the data by having them read through a lot of complicated CSV documentation or download a CSV template and then force their data to fit into it.
If engineering teams do take on creating a data normalization feature for a data importer to help with customer data onboarding, then they could end up building something that is just as time-consuming to create as the core product they're building that customers are actually paying for. The battle of manual vs. automatic is usually a question of where you want engineers to spend time.
Automatic data normalization
A new emerging technology helps teams save huge amounts of time on quality customer data onboarding. The Flatfile Data Exchange Platform includes advanced import functionality like data normalization, auto-column matching, data hooks, and more. Flatfile's data onboarding platform can also be implemented in as quickly as a day instead of 3-4 engineering sprints.
Why spend months building a data importer you can implement in one day? Flatfile, the pioneer of AI-assisted data exchange, provides companies and their software development teams with the easiest, fastest, and safest way to build the ideal data file import experience for their users. If you aren't sure what the right solution is for your business, contact Flatfile today. We've worked with hundreds of customers to solve their data exchange challenges, and we can help you build the solution that's right for you.
Data normalization is critical for ensuring data redundancies don't occur and that your team can work effectively with clean data. With most data exchange experiences, data normalization needs to be explicitly built into the data importer as a feature.
The choice between manual and automatic is up to you!
Stop wasting money
Download this free report to discover the missing piece that will help you reduce data errors and maximize revenue opportunities.
Editor's note: This post was originally published in 2020 and has been updated for comprehensiveness.
Anne Bonner
Writer
Share to

