Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
The first mile of every import is overlooked, but expensive

Damon Banks
Staff AI Engineer
Share to

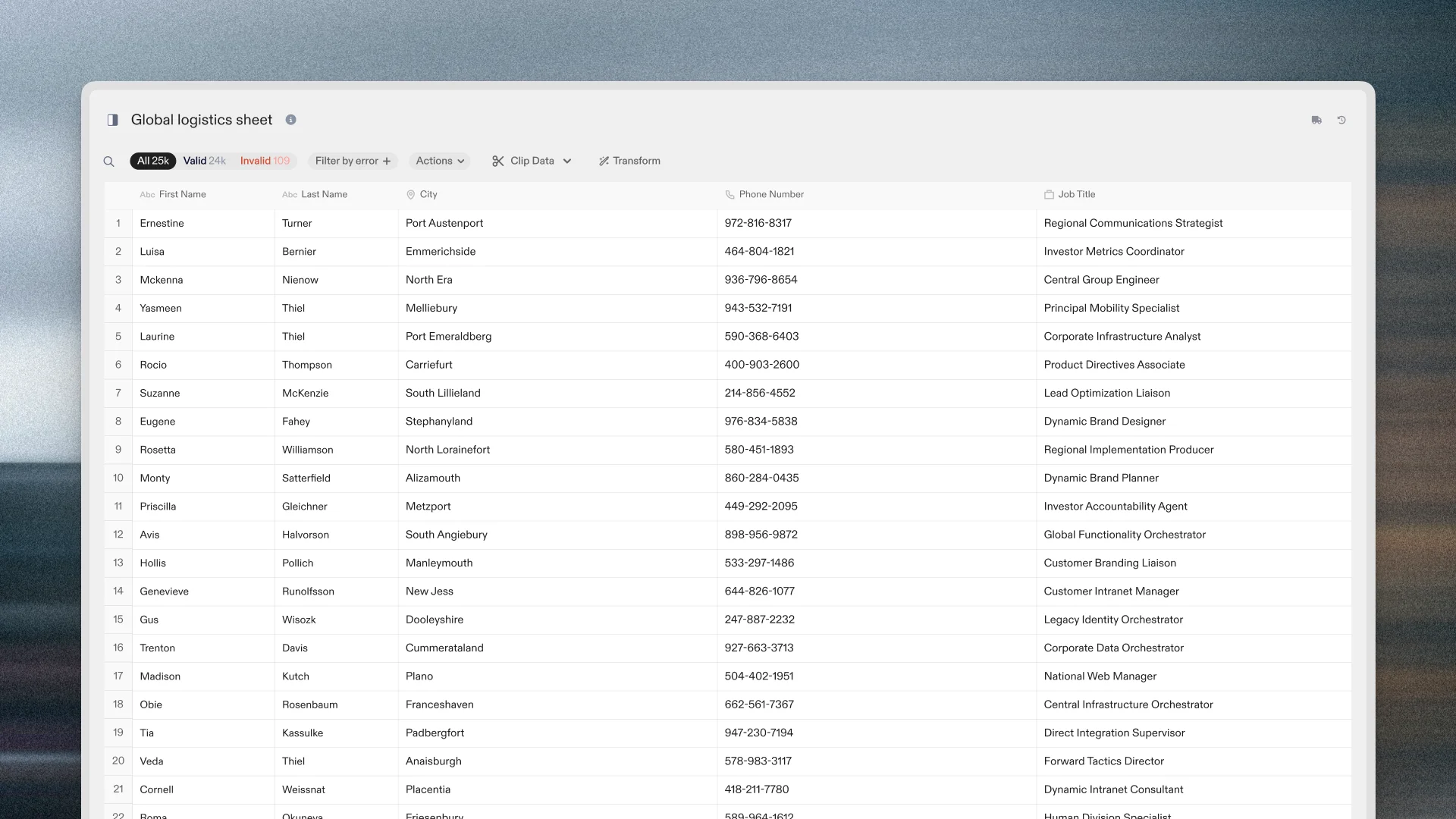
A customer’s spreadsheet arrives. You cross your fingers and open it—only to find it’s full of complexities like metadata, multiple header rows, and hierarchical data. And your system isn’t prepared to import any of that.
This hurdle is where a massive amount of time and effort gets spent. Compound the effects over dozens of onboarding or migration projects and you have some serious drag.
It’s the first mile of data projects. And it’s where projects risk losing momentum—and running up costs—before the “real work” even begins.
The work before the work
Before any schema mapping or data cleanup can happen, someone on your team has to make sense of how the file is structured.
Where the table actually starts, whether the header is complete or split across lines, whether there’s a second table hiding further down the sheet—there’s very little you can do with the provided data until you’re able to make sense of the format.
This work isn’t always accounted for when estimating project duration. You hope the files come in standard formats, ready to be imported and mapped. When that doesn’t happen, your team spends hours manually restructuring the data just to be ready to import—and the customer doesn’t feel the value from any of it.
Why most systems miss this step
Most software systems are designed to process data that’s shaped a certain way: clear headers, consistent rows, a standard tabular layout. But incoming files often carry structural quirks based on how they were exported, who generated them, or what context they were meant to capture.
Templates try to enforce consistency, but real-world exports don’t follow rules. Even files from the same system can vary depending on filters, report settings, and so on.
Historically, managing variability has been incredibly costly. Standardizing inputs has been the key to automation and scale. But just as AI is making personal, 1:1 software applications a viable path forward, it enables us to build solutions for data extraction that are unique to each file.
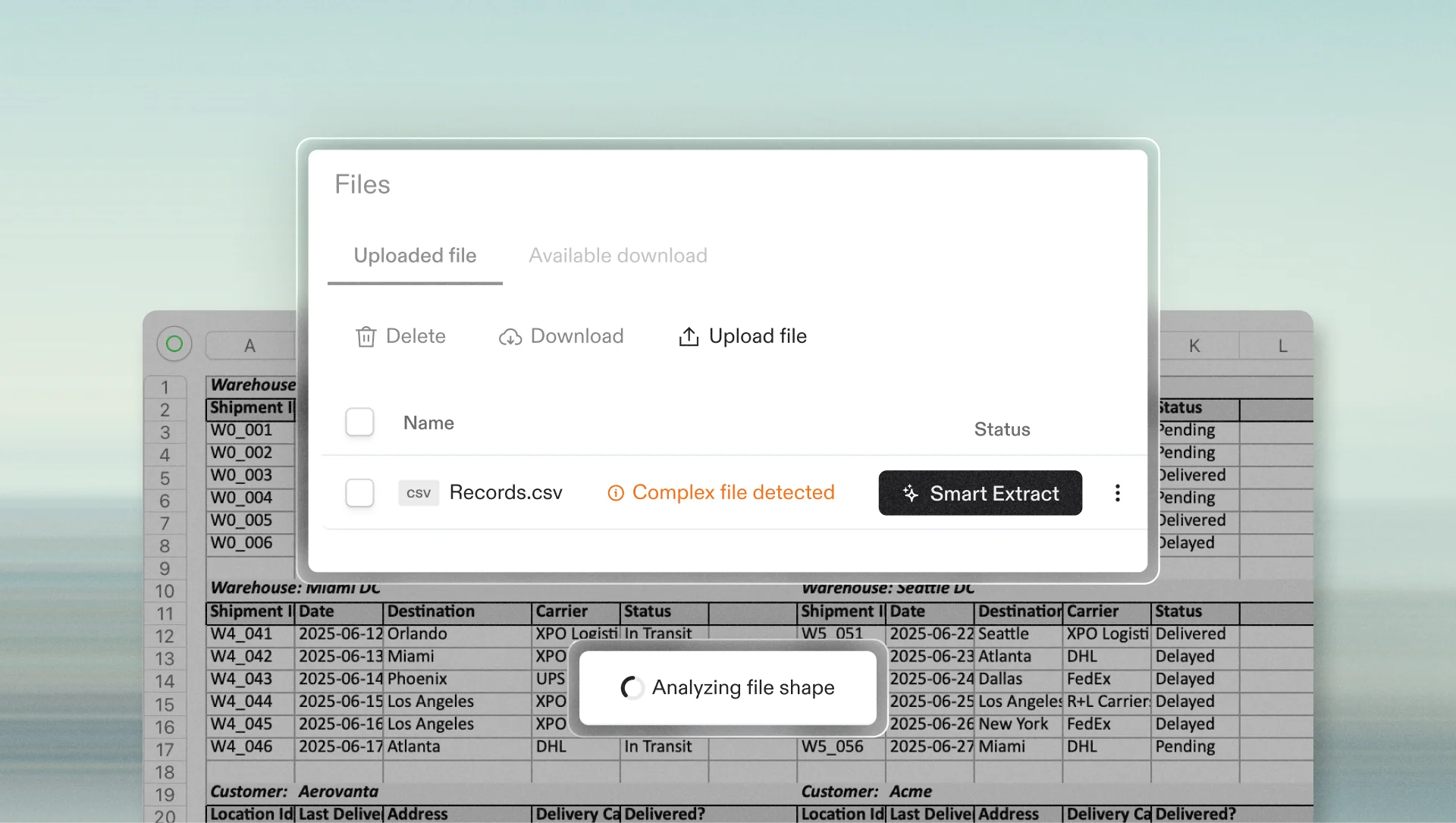
What Smart Extract does
When a file is uploaded to Flatfile, Smart Extract analyzes the structure and searches for complexities that a standard import can’t handle. Specifically, it’s looking for signs of the following:
Global or local metadata
Multiple header rows
Multiple tables within a sheet
Summary or total rows
Shifted data tables
Hierarchical data
When it encounters any of the above, Smart Extract writes a custom extractor to parse the data and bring it into Flatfile ready to work.
As with all of Flatfile’s AI-powered features, you’ll see a preview before you accept any actions made by the agent. If the structure shown isn’t what you need, or if there are any other issues with the proposed extraction, you can prompt the chat assistant to refine.
No more writing your own extractors or installing plugins to handle your more complex files—Smart Extract analyzes and executes in seconds.
What changes when you get the structure right up front
When Smart Extract interprets the file’s structure at upload, the rest of the process can begin immediately. There’s no need to prep the file in Excel or escalate to an analyst before you can begin the next step of mapping fields.
Implementation teams and their customers can review and adjust the extracted structure inside Flatfile instead of resolving layout issues offline. Analyst teams can reclaim the time they’d otherwise spend sorting through unique customer files. Project timelines aren’t held up waiting on reformatted versions of the same data.
It makes structure something the system handles, not the team. Instead of pausing to fix each file, teams can treat uploads as the starting point and move directly into mapping and review. No extra cleanup, no external prep work.
Why this was worth building
Smart Extract was built to handle the structural interpretation work that slows down every file import—work that’s usually manual, inconsistent, and hard to scale.
By appropriately structuring the file at upload, it shortens the time between receiving a file and putting it to use. Teams spend less time reformatting, customers aren’t asked to resend cleaner versions, and onboarding stays on track even when file structures vary.
It’s a practical change, but a productive one—fewer delays, less back-and-forth, and a process that holds up across dozens or hundreds of incoming files.
I'll be demoing Smart Extract in a webinar on August 5 at 1 PM ET. Register to attend here.
In the meantime, if you'd like to learn more, find the Smart Extract Knowledge Base article here.
Damon Banks
Staff AI Engineer
Share to