Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
The evolution of the primitive API

Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to

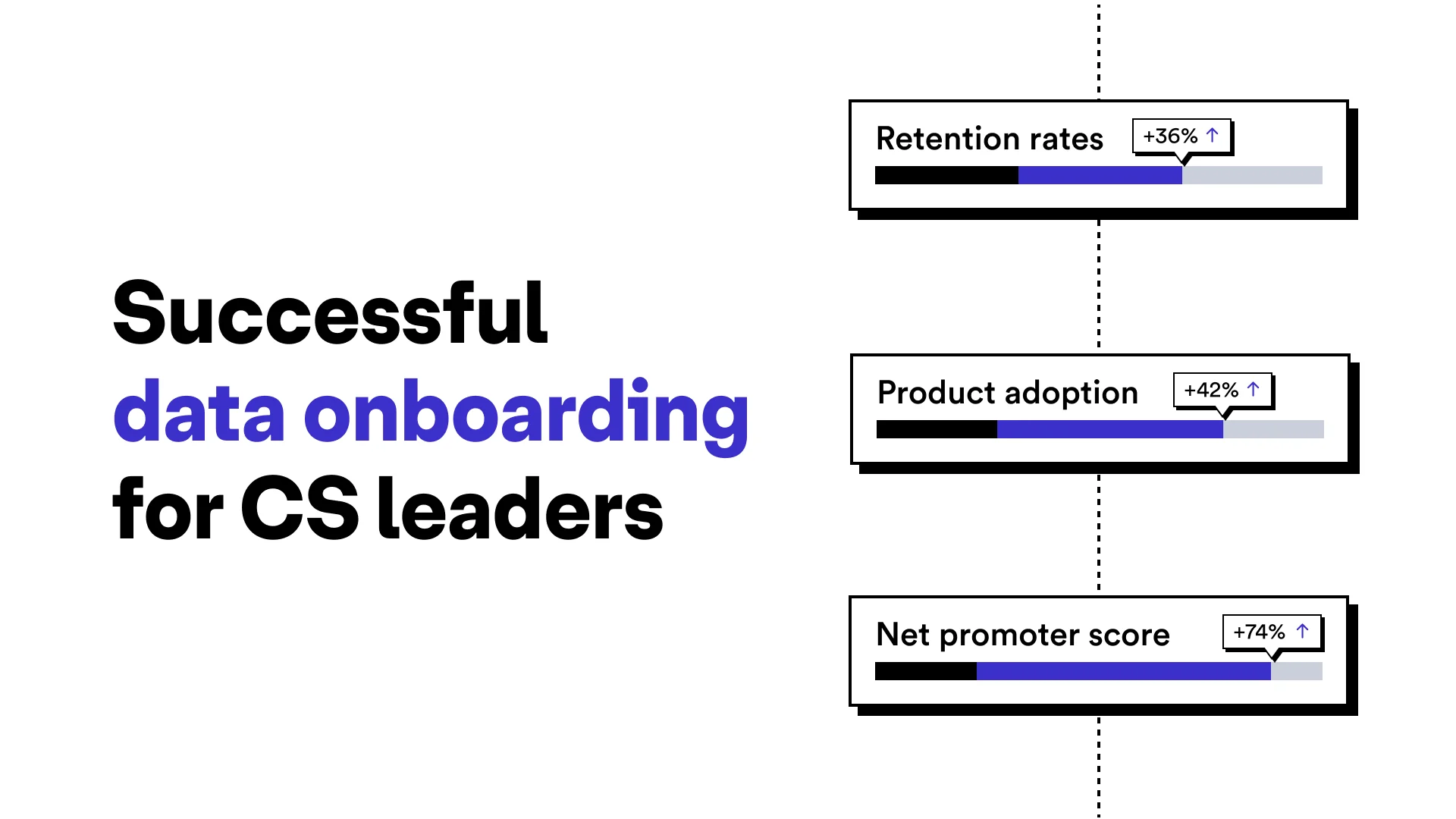
With the explosive growth of cloud computing and the Software as a Service (SaaS) business sector, unprecedented volumes of data — customer data, product data, statistics, financials — are being shared between organizations every day. And while it would be great if there were a universal API that could guarantee secure and accurate transfer of data, the reality is much more primitive. In a global market built upon powerful relational and object oriented database systems, the truth is that most of the data being shared between companies are CSV (comma-separated values) files. That’s right, the world literally and metaphorically runs on flat files.
Taming the Wild West of data
Back when gold was the standard currency in the United States, the relative simplicity of that precious metal presented some unique problems. First and foremost, gold is heavy and difficult to transport securely, which made it a favorite target of bandits in the Wild West. Flat files are much like the gold of that era — highly valuable to businesses and difficult to secure. Still, flat files remain the de facto standard in the Wild West of data sharing because they take up little space and are platform agnostic. But there is no standard for how we structure the data in those files and how they’re passed back and forth. That is left up to the people who manage them.
If you’ve ever had to head up a project to wrangle data from a new business partner, you know what a chore it is to prepare it for importing into your own database. Does the first row include header information? What is the correct date format? How many digits should postal codes be? These are among the easier questions to answer. Then you have to manage data that could be rendered useless or break your system if it is not in the correct format. And this is data that is mission critical to the functionality of your applications, populates your e-commerce platforms and can make the difference between profit and loss.
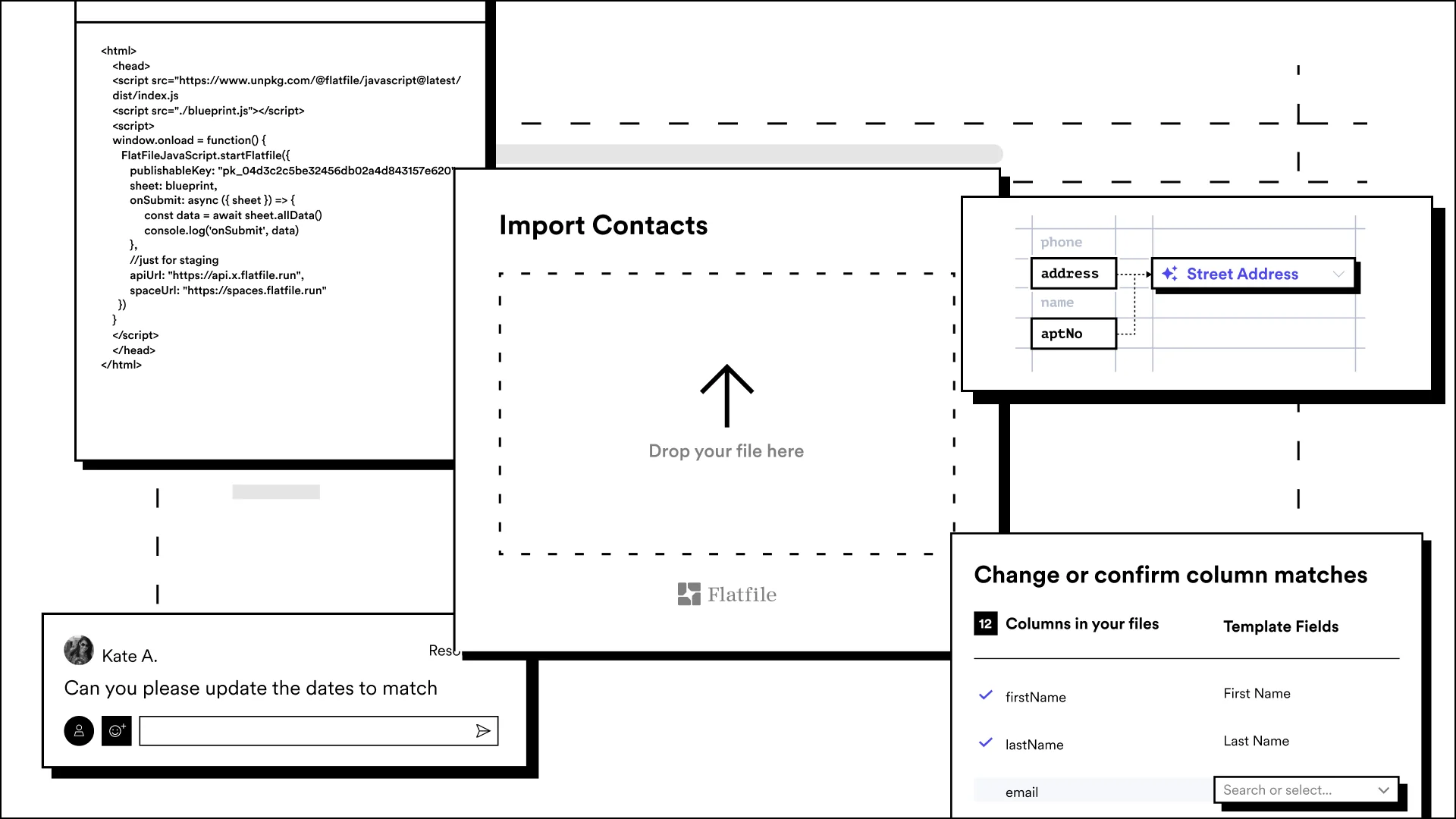
Faced with this problem, many businesses are forced to build their own solution to import CSV files, filter the data, flag anomalies, and correct the information. At first glance, this might seem to be an economical choice that gives you the most control over the finished product and frees up a few people from their data wrangling side job. But, turns out - custom solutions introduce their own set of difficulties. In fact, with CSV import specifically, it is a decision that could cost you more in the long run.
The hidden costs of building a CSV importer
A new product or feature assumes a commitment to supporting and maintaining it throughout its life cycle. The upkeep of these products typically becomes the responsibility of the team that created them - at least until they turnover anyway. Building a CSV importer is exactly that - a long-term commitment to another product, and one that is almost guaranteed to prove a distraction from your core business function.
Add another client with a different display language, and now you need to rebuild your importer. Acquire a client with massive data files? Now your importer can’t keep up. Does your client have customers in Ireland? Now you have to figure out how to add GDPR into your importer. In short, making a flawless, scalable data onboarding solution is not as simple as it looks. (Trust us, we know.)
Remember: as far as data exchange goes, it is still the Wild West out there and there is no guarantee that what is built will work for your next use case. That next upload? Well, it will probably include data of an entirely different sort, requiring you to — yet again — update your solution.
Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to