Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
Taming the Wild West of data

Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to

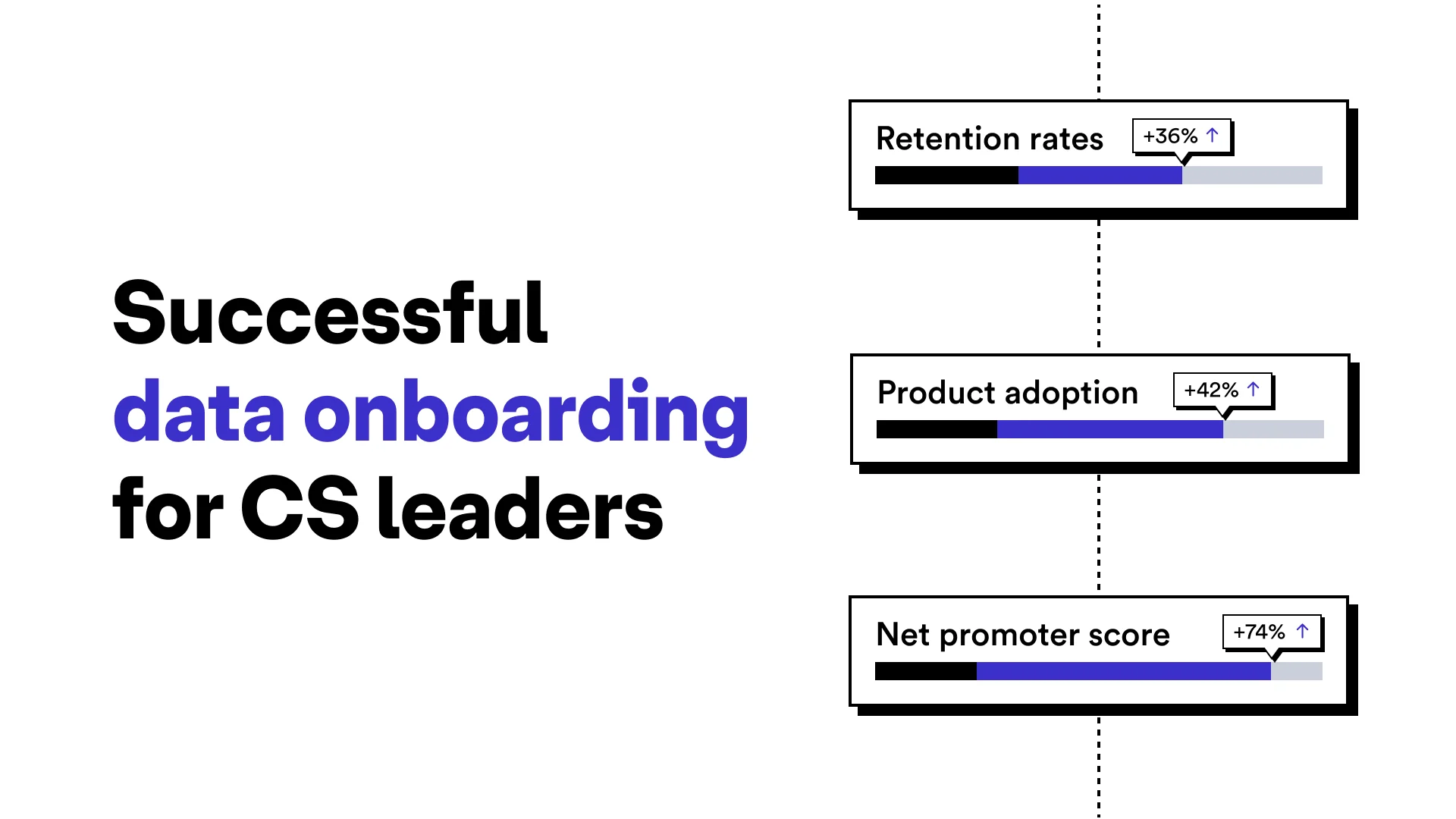
The world is increasingly data driven. From multinational companies with complex supply chain management (SCM) systems to regional hospitals storing sensitive patient data, global organizations large and small rely on data to keep them going.
Most of the databases that support these organizations are built and maintained by talented administrators who understand the particular needs of the organization, and can design a table structure that accommodates all the necessary security and efficiency requirements. But therein lies the root of a particularly nasty problem. These systems, for the most part, are not interconnected, nor are they built using the same structure. The result is an environment where the most coveted commodity (information) is being stored without a set standard for how it is structured. It is a Wild West of Data, where rules and best practices are shot from the hip. But there’s a new sheriff in town — and their name is Flatfile.
If all this data were to just stay put, we wouldn’t have much of a problem. But when companies acquire new customers, merge with other businesses or align themselves with a business partner, they need to share data. When it comes time to exchange that data, they need to export it into a file format that is reliable, universally accessible, and fast.
Developed in the age of mainframe computing, a decade before the first personal computers, the comma-separated value (CSV) file format has been the “chosen one” for this very purpose.
The anatomy of a CSV file
Behold the humble comma. Who would have thought that this tiny mark could be the sole arbiter of where a data point begins and ends. To those of us who work with flat files, however, these marks, or more precisely, what lies between them, is the well from which we drink.
Creating a CSV file is as simple as entering data into a text file using commas to offset your data points and then saving the file with the “.csv” extension.
Here is an example of what the contents of a CSV file might look like:
Last Name,First Name,Full Name,Birthday
Jones,William,William Jones,09-13-1954
Jones,Nancy,Nancy Jones,10-30-1998
Hadad,Sophie,Sophie Hadad,02-22-1991
Levitt,Frank,Frank Levitt,05-11-2004Figure 1. Sample Contents of a CSV file
This is nothing more than a simple list of names and birthdates. The first line of the file represents the first row of the data, which may or may not be designated to hold header information. In the example above, the first line is indeed a header row that tells us what type of information is stored in each column: Last Name, First Name, Full Name, and Birthday, respectively.
Any information following the header row represents the contents of each column and row in the data table. So, if the header row already occupies the first row, then the first line of actual data is going be displayed in a spreadsheet as follows:
[Row 2: Column A],[Row 2: Column B],[Row 2: Column C], and so on.As you can see from Figure 1, there are no spaces between data points unless the space is explicitly part of the data, such as in the header designations “Last Name��” and “First Name”, and all of the data in Column 3 (“Full Name”).
What you might also notice about a flat file is what it doesn’t have. There are no table borders, there are no visible columns or cells, there are no mechanisms to sort the information, etc. And if you imagine Figure 1 extended to include hundreds of columns and rows, you can soon understand just how daunting a CSV flat file can get when operating at the enterprise level.
Once you learn to recognize a flat file, its structure is straightforward. But reading one with the naked eye is a recipe for fatigue. And for this reason, we build user interfaces (UIs) to help us sort and present the data in a readable format or even in a visualized representation such as a chart or graph.
There is no roadmap to CSV Formatting
While understanding the nature of a CSV file is fairly easy, from this simplicity comes a world of confusion. The Wild West of Data is a place where sometimes the first name comes first and sometimes it comes last; where US postal codes may comprise 5 digits or 9 digits depending on who entered the data; where dimensions may be documented in metric or imperial units; and where the order and names of each of these columns may be spelled, designated and formatted in any number of perfectly legal and acceptable, yet maddingly differing ways. Ask any data manager and they will tell you: Making heads or tails of flat files can take weeks or months before you even get to start working with the data.
That delay means that new customers cannot be contacted, new products cannot be sold, new research cannot be applied, and new business cannot be accounted for — all because you are waiting for your flat files to be cleaned and imported.
The answer is simple
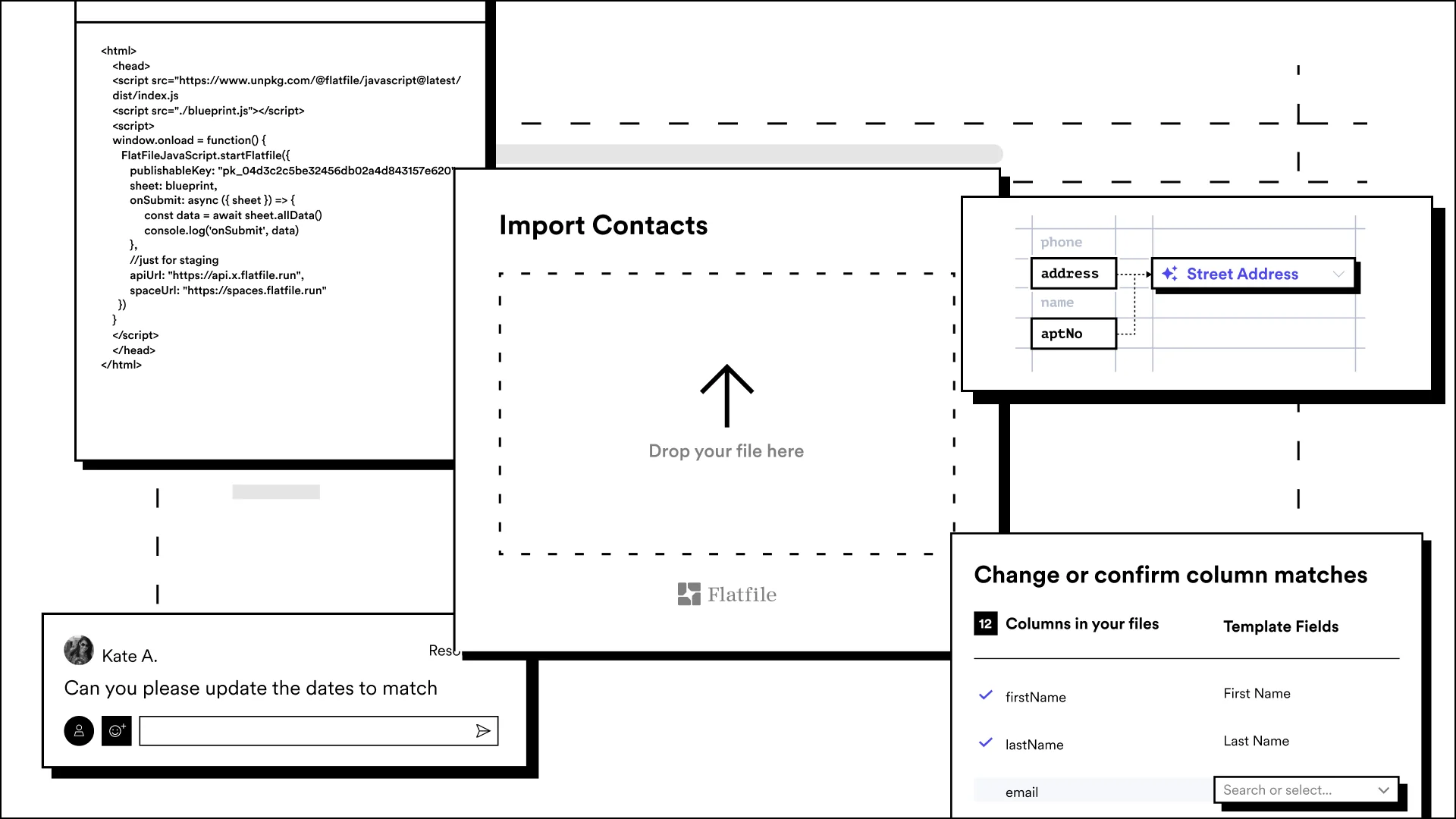
Flatfile was established by people who had finally pulled enough of their own hair out trying to ride the bronco that is the Wild West of Data. Flatfile was created to solve the problem of preparing data to be exchanged and allowing work to progress quickly, efficiently, and securely. Flatfile enables you to move thousands of data records with lightning speed, time and time again. It achieves this by creating templates that can be infinitely customized to match the structure of any CSV file you might encounter and then reused the next time you need to exchange data between the same sources. Templates can also be easily modified to accommodate revisions in data structure, ensuring that your data will always be in proper order. More than just templates, however, Flatfile is an intelligent technology platform that guides you through the process of cleaning your data. It quickly identifies anomalies, errors, inconsistencies, and missing data and works to solve the problems associated with data exchanges at enterprise scale.
Flatfile isn’t an app, it isn’t a service and it isn’t an importer. It is a fully customizable engine for data exchange that you can use in-house, in the cloud, and share with your business partners. You can build our technology directly into your own applications using the Flatfile API or send your partners a simple link to a front end portal that will guide them through sharing their data with you. We’ve unleashed the underlying technology of Flatfile to make it available to any business anywhere in the world.
But all of this superlative talk means nothing until you see Flatfile in action. The short version of this story is that we set out to create a game-changer in data exchange and we are convinced that we have succeeded. Why not take a look yourself and see if you agree?
Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to