Flatfile is now Obvious
We've renamed our company to Obvious, which is also the name of our newest AI agent. Obvious helps you migrate and analyze data, create reports, generate presentations, and connect all of your tools—in one collaborative workspace.
Check out Obvious
Do more, faster with Flatfile's new parallel processing

Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to
From sending a Slack message while on a video call, to watching TV and scrolling Facebook before bed, most of us spend our time doing a couple things at once. For low pressure tasks, it’s mostly of little consequence, but the reality is the more things we try to do in parallel, the less efficient we are.
Computers are a different story. They can run two or more tasks simultaneously without affecting efficiency using a technique known as parallel processing.
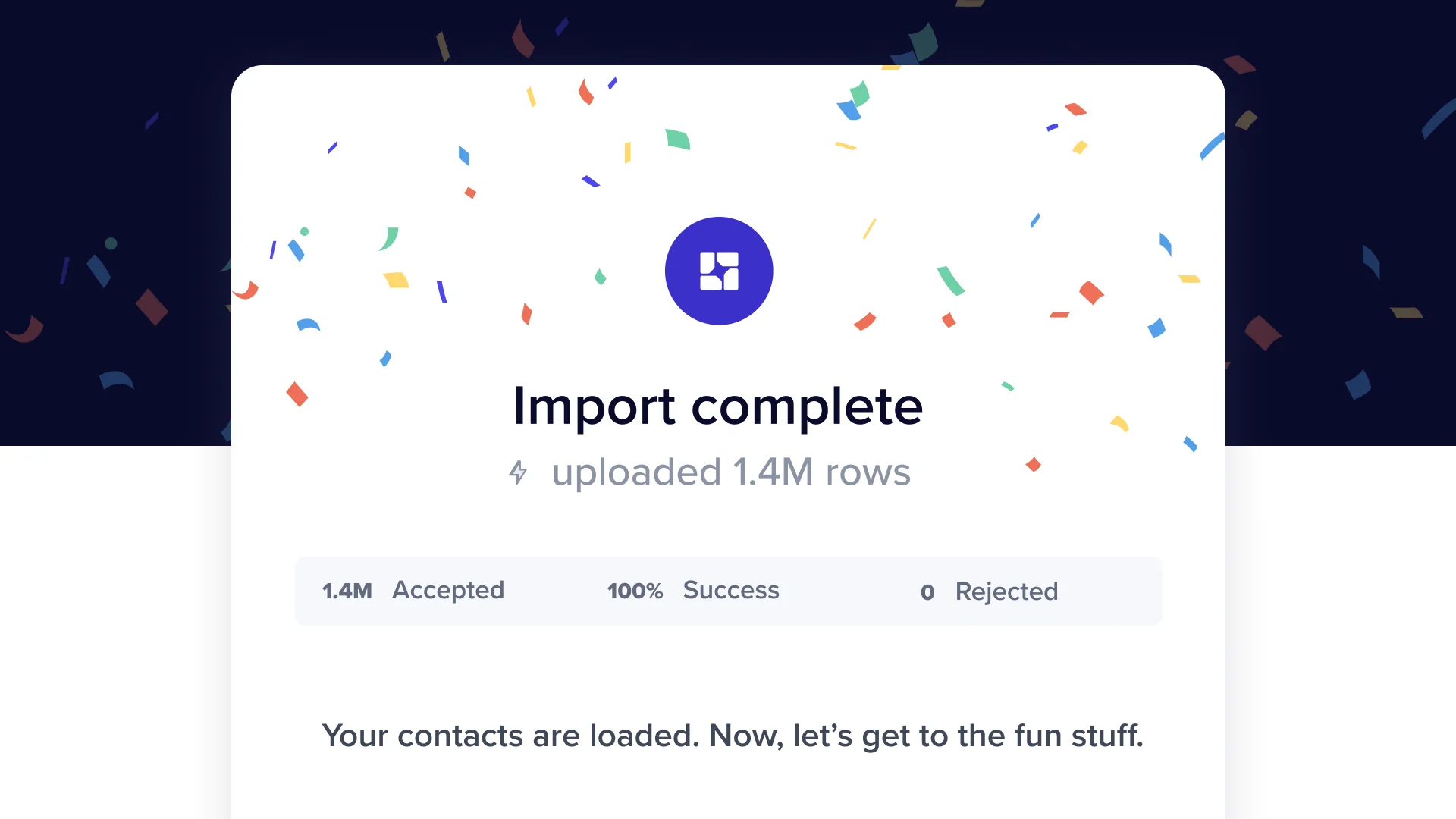
Parallel processing can be credited for many achievements, from mapping the orbits of black holes to complex models that predict the future of the economy. Now, parallel processing can be credited with a new achievement: earth-shattering data import speeds in Flatfile.
Flatfile’s engineering team has been working around the clock obsessing over one thing - performance during data import. We quietly deployed parallel processing last week, and we’re thrilled to share some early results:
Massive files with hundreds of thousands of rows are moving through with ease, thanks to workers that dynamically scale as files increase in size.
Import times for the largest files have noticeably decreased.
Flatfile's ability to process large files is just one of many reasons to ditch your homegrown importer. With enterprise compliance and security to boot, what more could you ask for?
Our continued commitment to speed, reliability, and compliance makes the decision to choose Flatfile over homegrown solutions easier than ever. With 1.8 billion records processed and counting, Flatfile gives the world’s best companies a centralized platform for better data onboarding.
Talk soon,
Ashley Mulligan, Head of Marketing
Ashley Mulligan
Head of Growth Product & Developer Experience in Engineering
Share to